

A gentle introduction to DSPy for graph data enrichment

AI Engineer at Kùzu Inc.
Constructing real-world knowledge graphs often involves combining or merging data from multiple sources. However, the same entity may be represented in different ways across these sources, leading to challenges in disambiguating similar-looking entities that we can merge into a unified dataset. If you’ve ever faced this kind of problem when working with graphs or data in general, you’ve come to the right place!
In this post, we’ll showcase a two-part workflow involving vector embeddings and an “LLM-as-a-judge” to disambiguate entities so that we can enrich one dataset with information from another. The LLM part of the workflow uses DSPy, a declarative framework for building compound AI pipelines. The goal of this post is to give a gentle introduction to DSPy and the powerful primitives it provides, so that you can repurpose these ideas and be more productive applying LLMs in your own domains.
Motivation
Graphs are a powerful way to represent complex relationships between entities — finding centres of influence within a network can yield valuable insights in numerous domains. A particularly interesting graph that we’ll use in this post, is the Nobel laureate mentorship network, which captures the professor-student relationships of Nobel laureates and candidates (termed “scholars”). Asking about which scholars were particularly influential in the mentorship network of Nobel laureates is, inherently, a graph question, because it involves analyzing the deeply interconnected mentorship relations1. Wouldn’t it be fascinating to create and explore such a knowledge graph2?
Primary data source
We use a dataset of Nobel laureates and their mentorship relationships1 from this repo. After some data wrangling to get the information out of the original format, we end up with a nested JSON structure that captures the parent-children relationships between laureates and their mentors. The information about each scholar only includes their name, type (“laureate” if they won a Nobel prize, or “scholar” if they did not), and category and year of the award (if applicable). Only four categories are included in this dataset: Physics, Chemistry, Medicine, and Economics, with all prizes being awarded between the years 1901-2021.
[
{
"children": [
{
"name": "George Smith",
"type": "laureate",
"category": "Physics",
"year": 2009
}
],
"parents": [
{
"name": "Andrew Lawson",
"type": "scholar"
}
]
}
]This primary source data is useful to understand the mentorship structure, but it doesn’t contain deep enough information on each laureate instance, such as their city or country of birth, their gender, etc. — so this limits the kinds of questions we can ask about the entities in the graph.
Enrichment data source
To augment or enrich this primary data, we use the official Nobel Prize API, which provides high-quality data about the laureates, including their biographies, birth dates, affiliations, and more. The API is well-documented and easy to use, returning rich data about each laureate in a structured format.
[
{
"id": "840",
"knownName": "George E. Smith",
"givenName": "George E.",
"familyName": "Smith",
"fullName": "George E. Smith",
"gender": "male",
"birthDate": "1930-05-10",
"birthPlaceCity": "White Plains, NY",
"birthPlaceCountry": "USA",
"birthPlaceCityNow": "White Plains, NY",
"birthPlaceCountryNow": "USA",
"birthPlaceContinent": "North America",
"deathDate": null,
"prizes": [
{
"awardYear": "2009",
"category": "Physics",
"portion": "1/4",
"dateAwarded": "2009-10-06",
"motivation": "for the invention of an imaging semiconductor circuit - the CCD sensor",
"prizeAmount": 10000000,
"prizeAmountAdjusted": 13471654,
"affiliations": [
{
"name": "Bell Laboratories",
"nameNow": "Bell Laboratories",
"city": "Murray Hill, NJ",
"country": "USA",
"cityNow": "Murray Hill, NJ",
"countryNow": "USA",
"continent": "North America"
}
]
}
]
}
]The problem is that there doesn’t exist a direct mapping between the laureates in the primary source (which have only names, often partial names) and the official Nobel Prize API source data, which contains much richer information as shown above. This means that we need to use an alternative means to merge these two data sources. Once this is done (as per the methodology discussed below), the resulting knowledge graph in Kuzu looks something like this3:
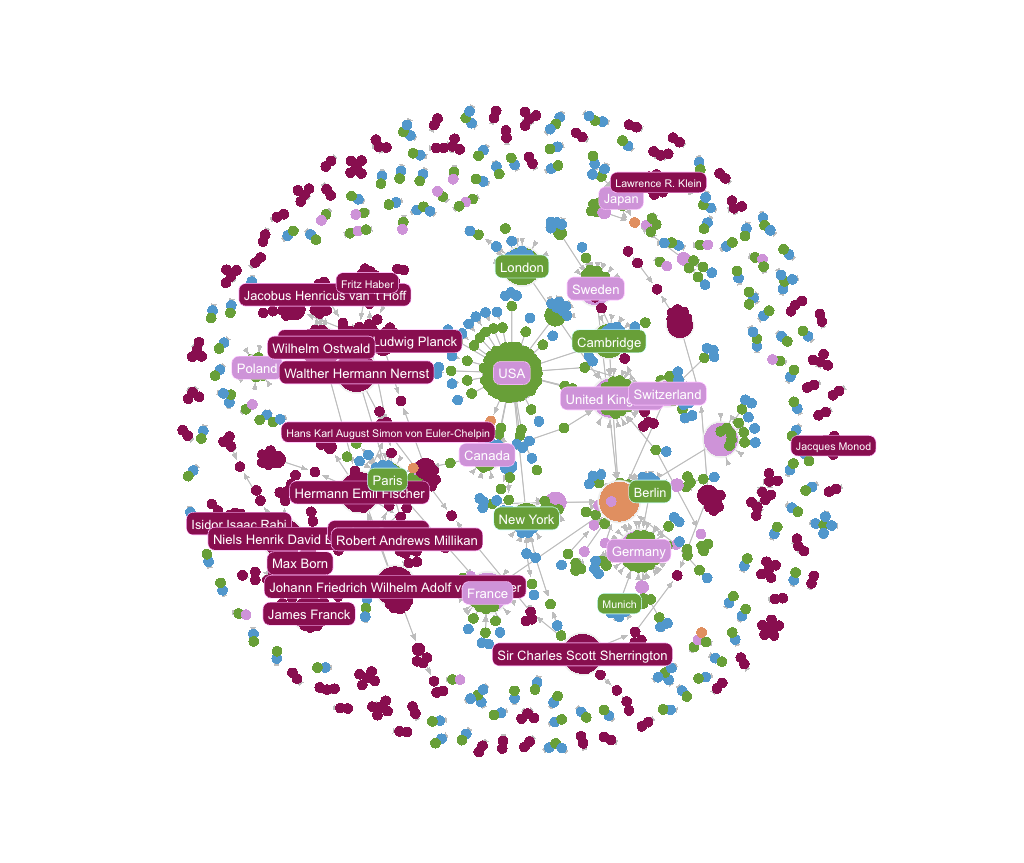
This is much more interesting! The graph constructed from the enriched data contains a lot of information that was not in the primary source, which means we can now answer questions like this:
- How many Physics laureates were born in the US but were affiliated with University of Cambridge?
- Who were the mentors of female laureates that won the Nobel Prize in Chemistry?
- Which laureates were mentored by other laureates affiliated with non-US institutions?
As a bonus, the primary data source (the mentorship network) contains scholars dating back hundreds of years, all the way to the 16th century, to the days of Galileo and Isaac Newton 🤯. So we can also explore historical trends in mentorship that shaped the landscape of today’s prize winners.
Methodology
To enrich the primary data, we need to ascertain (with a high degree of confidence) whether a given laureate in the secondary dataset is an exact match with the laureate mentioned in the primary data. To do this, we’ll need to compare not only the names of the laureates, but also the prize category and the year they won the prize.
Rather than writing complex rule-based logic to compare substrings of names and other attributes, we can use an LLM pipeline orchestrated by DSPy. For each laureate in the primary data, we’ll use vector search retrieve the top most-similar laureates (based on name, category, and year) from the secondary data. This set of top names from the secondary data is sent as context to an LLM to determine which of them is the exact same person as the primary data laureate.
It’s natural to wonder: why use LLMs at all? Why not only use vector similarity scores to judge if two laureates are the same? In practice, this doesn’t work well, because there are several cases where the names of the same laureates are spelled drastically differently (“John Strutt” vs. “Lord Rayleigh”4), or where multiple unrelated laureates have very similar names (“George E. Smith” vs. “George P. Smith”). When given sufficiently good context, for e.g., by combining the full name with the Nobel prize category and the award year, LLMs are very good at acting as judges to disambiguate between entities.
Let’s summarize the key parts of our methodology:
- Vector search: Use vector embeddings to find the top most-similar laureates in the secondary data for each laureate in the primary data.
- LLM-as-a-judge: Use an LLM to judge which of the top most-similar laureates is the exact same person as the primary data laureate.
At the end of the second stage, we get a mapping of IDs between the two datasets, which is sufficient to merge the two such that we have a single unified graph with all the information needed to answer a wider range of questions.
Why DSPy?
DSPy (Declarative Self-improving programs in Python) is an open source Python framework that provides powerful primitives to program, not prompt, LLMs. For workflows that involve multiple steps, DSPy allows you to concisely and elegantly mix together LLM-driven functions with deterministic functions, allowing for greater flexibility in building and reasoning about complex workflows.
The conventional way to build such an AI pipeline is to write prompts as strings and pass templated variables to them. In DSPy, no prompts are written by a human. Instead, you declare your intent via your program (e.g., Python), and the framework automatically generates (and if needed, optimizes) the prompts for you. There are three fundamental primitives in DSPy that are important to know about:
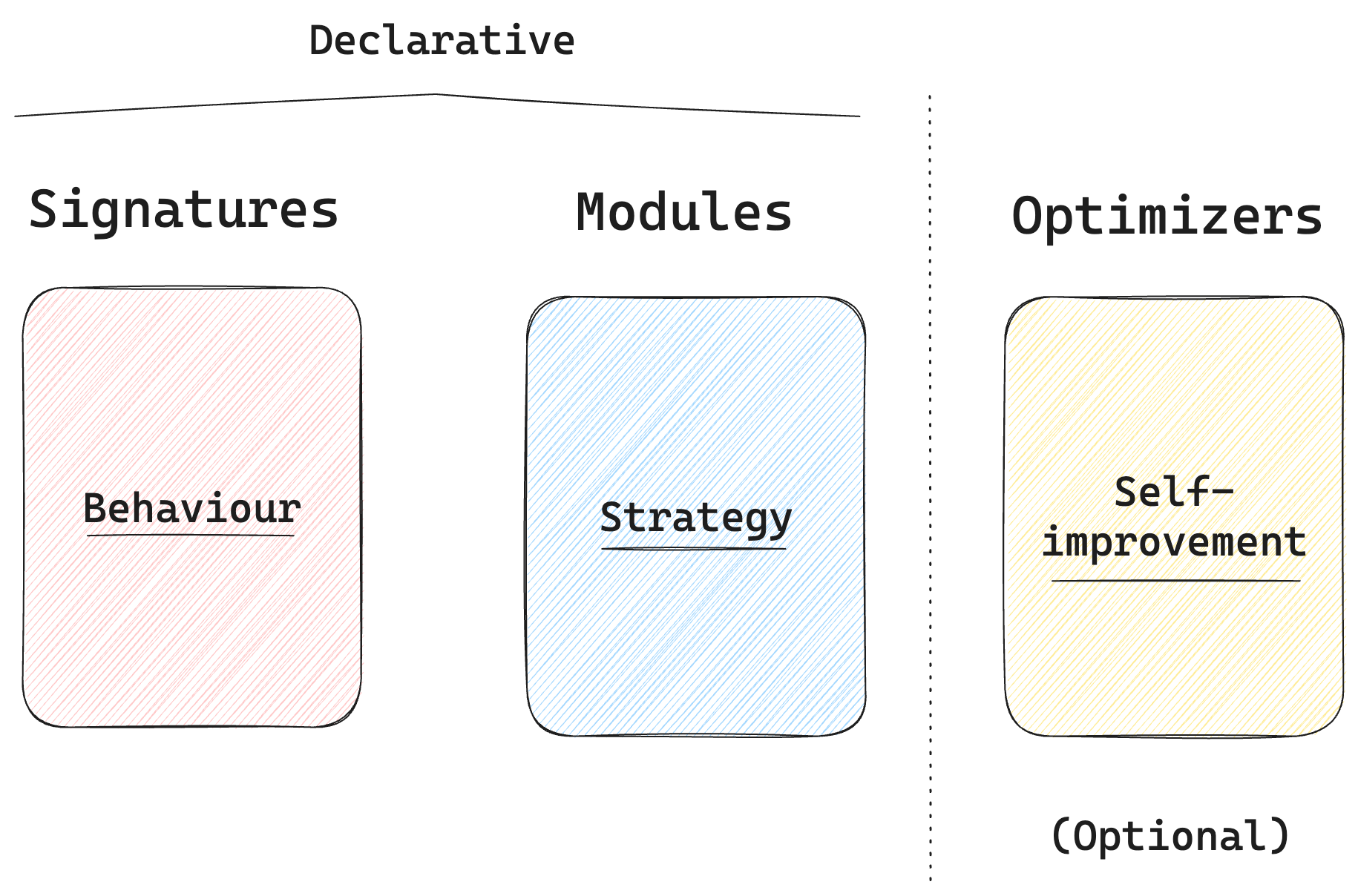
- Signatures: A
Signatureallows you to define the behaviour of your pipeline, via a type system that specifies input and output types to the LLM. A signature lets you tell the LLM what it needs to do, rather than specify how it should do it. - Modules: A
Moduleis the core building block of an LLM pipeline in DSPy. It’s generalized to handle any signature, and it lets you define the strategy for how to prompt the LLM. DSPy modules are composable, meaning that you can combine multiple modules together to create a more complex module. Two common built-in modules in DSPy are listed below, but there are several more described in their docs.- A
Predictmodule simply asks an LLM to predict the output given an input - A
ChainOfThoughtmodule combines multiplePredictmodules with some additional logic for reasoning over the inputs before making a final prediction
- A
- Optimizers: You can use an
Optimizerto improve the performance of a DSPy module with annotated examples of input-output pairs. The optimizer will automatically generate and improve the prompts or the language model weights to produce a new, improved module that can perform better on the same task with the same language model.
To sum up, DSPy does away with the traditional notion of “writing prompts by hand” — instead, you declare your intent via the program itself, using signatures and modules that define the behaviour and strategy for interacting with the LLM. Using optimizers is totally optional — for this introductory post, we’ll not be using them, instead just sticking with DSPy’s automatically generated base prompts.
Workflow
Vector indexing
The first step in our workflow is to create a vector index of key properties of the laureates in both datasets so that we can use vector search to build the context for the LLM-as-a-judge downstream. Each entry in the primary dataset is transformed into a vector embedding and stored in Kuzu, which provides a fast and convenient-to-use vector index.
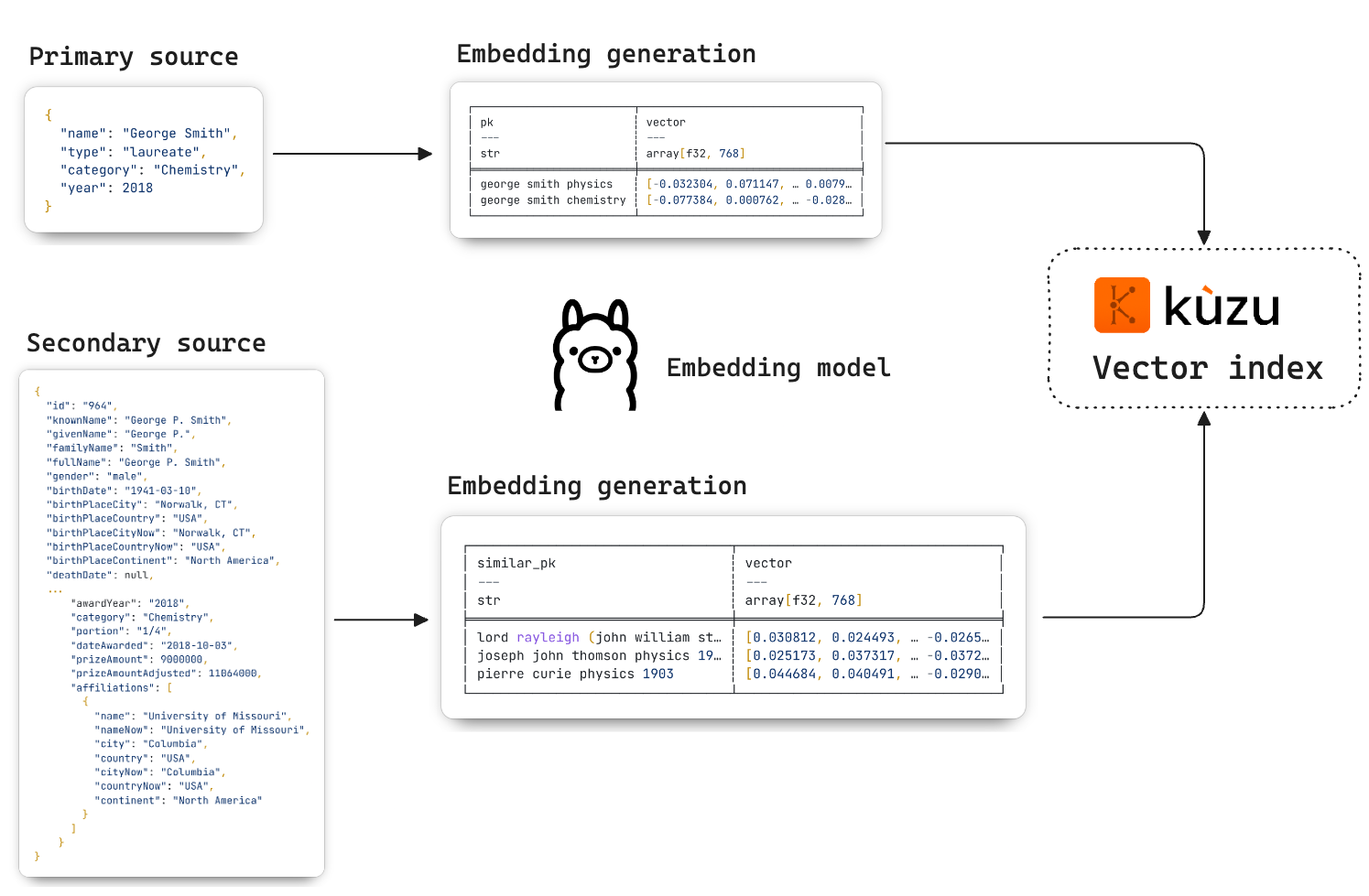
Two separate node tables are created in Kuzu for laureates from each data source. The embeddings are
created using an embedding model (nomic-embed-text in Ollama) and stored as a new column in
each node table as shown in the diagram above. Once the embeddings are ingested into Kuzu, we can run the
CALL CREATE_VECTOR_INDEX command to create a vector index on either table.
If you’re interested, the code for these steps is available here.
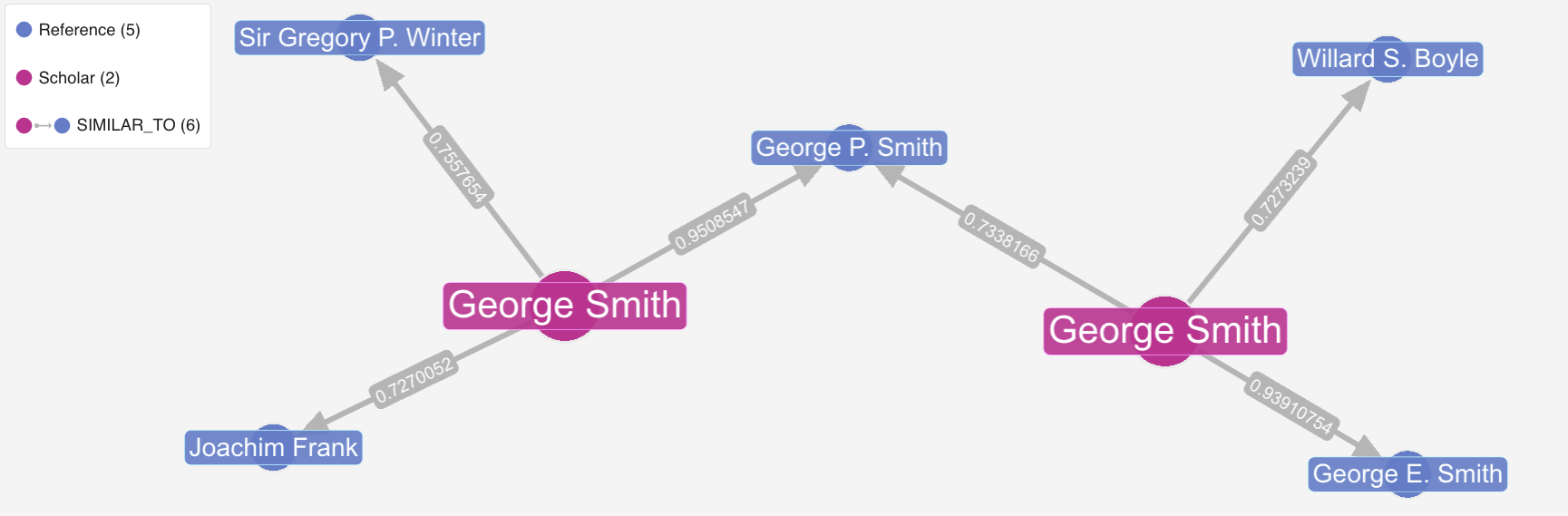
To test the quality of the embeddings, we can run a simple vector search query in Kuzu to find the top most similar
laureates in the secondary dataset for a given laureate in the primary dataset. The image below shows the
results of such a query for the laureate “George P. Smith” (2018 Chemistry laureate) who has the same first
and last name as “George E. Smith” (2009 Physics laureate). Because the embeddings are generated from (full name, category, year), the primary node “George Smith” on the right is most similar to “George E. Smith”,
because the term “physics” that’s used in the embedding, increases its similarity to the latter
(who won the Physics Nobel prize).
LLM as a judge with DSPy
We’re now ready to begin the second stage of our workflow: using DSPy to help disambiguate the laureates from either dataset. Each component of the pipeline is explained below.
Language models
DSPy supports several language models through the LiteLLM interface, allowing you to use any
LLM as its backend provider. Below, we show how to set up a language model in DSPy using OpenRouter
with the google/gemini-2.0-flash-001 model, but you can switch to any other LLM provider
you prefer.
import dspy
# Using OpenRouter. Switch to another LLM provider as needed
lm = dspy.LM(
model="openrouter/google/gemini-2.0-flash-001",
api_base="https://openrouter.ai/api/v1",
api_key=OPENROUTER_API_KEY,
)
dspy.configure(lm=lm)Types
To define the types of the input and output for our DSPy pipeline, we use Pydantic models. These models will be used to define the signatures of the DSPy modules that we create later.
from pydantic import BaseModel
class Scholar(BaseModel):
# This is from the primary dataset
name: str
category: str
class Reference(BaseModel):
# This is from the secondary dataset (Nobel Prize API)
id: int
knownName: str
fullName: str
category: strFor this example, our data model is simple: we have a Scholar type that represents
the laureate in the primary dataset, and a Reference type that represents the laureate
in the secondary dataset. We want a mapping for each and every scholar name in the primary dataset
to an id in the secondary dataset, so that we can confidently merge the two datasets.
Signatures
We can now define a DSPy Signature that defines the behaviour of our DSPy module. This is done
by specifying the input and output types that the module expects, along with an optional description
of each field. The contents of the docstring are also important — DSPy will append these to
the system prompt that it generates.
class EntityHandler(dspy.Signature):
"""
Return the reference record `id` that's most likely the same person as the sample record.
- The result must contain ONLY ONE reference record `id`
- Also return the confidence level of the mapping based on your judgment.
"""
sample: Scholar = dspy.InputField(desc="A sample scholar record")
reference_records: list[Reference] = dspy.InputField(
desc="A list of reference records from the official Nobel Prize API"
)
output: int = dspy.OutputField(desc="Most similar reference record to the sample record")
confidence: Literal["high", "low"] = dspy.OutputField(
desc="The confidence level of mapping the sample record to one of the reference records"
)Fields marked by dspy.InputField() are inputs to the module, and those marked by dspy.OutputField()
are outputs. For the outputs, we ask for an integer value that represents the id of the reference record,
and a literal string value that indicates the LLM’s confidence level in the mapping. If the
context provided to the LLM is insufficient, we’d expect the LLM to return a “low” confidence level5.
Modules
DSPy allows you to define custom modules with ease, but
for this case, the built-in Predict module is sufficient6. This is defined as an async function
in Python that takes in a single sample record (from the primary dataset) and a list of reference records
(secondary dataset), and returns the output as defined in the EntityHandler signature.
async def execute_entity_disambiguation(
sample: Scholar, reference_records: list[Reference]
) -> tuple[int, str]:
"""
Execute the DSPy entity disambiguation module.
The approach is similar to "LLM as a judge". The LLM is given a list of reference records
and a sample laureate record, and it needs to determine which reference record is most likely
the same person as the sample laureate record.
"""
handler = dspy.Predict(EntityHandler)
result = await handler.acall(sample=sample, reference_records=reference_records)
return result.output, result.confidenceThe above snippet defines an async function, and involves just a couple of lines changed from
the regular sync Python function. You simply instantiate the built-in DSPy Predict module and pass in
the Signature object that we defined earlier. The acall method is used to call the module asynchronously,
and you can await results in an async context.
💡 What does DSPy’s generated prompt look like?
It’s worth taking a moment to understand what DSPy actually does to help the user avoid writing manual prompts
by hand. Under the hood, the DSPy Module uses an Adapter
that takes the Signature and the input data,
and applies the information from the type system of the language (in this case, Python) to generate a prompt
that looks something like the example below. On the left is the signature and module declaration,
and on the right are the system and user messages that DSPy generates as part of the prompt for the LLM.
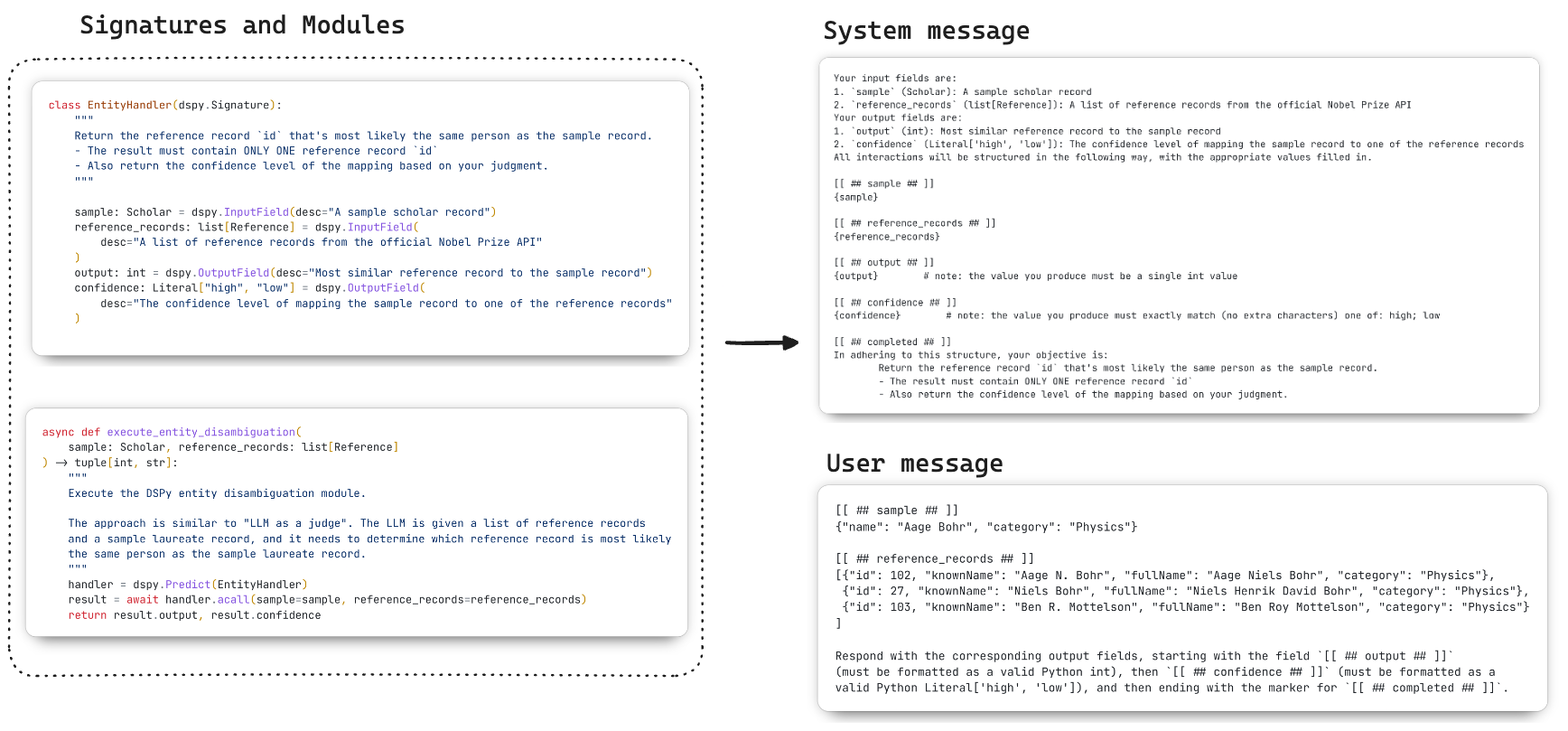
You can always inspect the generated prompts by calling the dspy.inspect_history() function.
If you’re interested, see a more readable version of the
generated prompt here.
Run the DSPy pipeline
Now that we’ve defined the LLM, types, signature, and module, the next step is to run the DSPy pipeline
end-to-end and return a mapping of IDs between the two datasets.
To collect the most similar reference records for each scholar in the primary dataset,
we can use the following vector search query function in Kuzu and from the result, coerce each
object to the Reference Pydantic type defined above.
def get_similar_records(
conn: kuzu.Connection, vector: list[float], topk: int = 3
) -> list[Reference]:
"""
Get top-k most similar reference records via vector search.
"""
result = conn.execute(
f"""
CALL QUERY_VECTOR_INDEX(
'{table_name}',
'{index_name}',
$query_vector,
$limit
)
RETURN node.id AS id, node.knownName AS knownName, node.fullName AS fullName, node.category AS category, node.awardYear AS year
ORDER BY distance;
""",
{"query_vector": query_vector, "limit": topk},
).get_as_pl()
result = result.select("id", "knownName", "fullName", "category", "year")
# Below, we randomly shuffle to ensure that the LLM's reasoning ability is exercised
# If we don't shuffle, the correct answer will likely always be the first in the list
# because that's what vector search returns
result = result.sample(n=len(result), shuffle=True)
return [Reference(**row) for row in result.to_dicts()]Note how we randomly shuffle the results to actually convince ourselves that the LLM is reasoning about the context and not just returning the first result as the answer every time. The full code that runs the DSPy module after vector search is available here.
The output from our DSPy pipeline is a list of records that looks like this:
[
{
"source": {
"name": "George Smith",
"category": "Chemistry",
"year": "2018"
},
"matched_record": {
"id": 964,
"knownName": "George P. Smith",
"fullName": "George P. Smith",
"category": "Chemistry"
},
"confidence": "high"
},
...
]We now have a mapping of the name from the primary dataset to the id of the matched record in the secondary dataset!
For this simple use case, 100% of all the records returned were matched with a “high” confidence level, which is
great. However, in other scenarios, you may find that the LLM returns a “low” confidence level for some records,
so it’s worth inspecting those cases more deeply to see if the context provided to the LLM is sufficient for it to
make a judgment.
Create final graph in Kuzu
The mapped objects from above are then used to merge the two datasets, allowing us to then create a unified graph that incorporates all the information about laureates and their mentorship relationships. The graph is created using a combination of Polars DataFrames and Pydantic, and persisted to a Kuzu database. The schema of this graph contains the following nodes and relationships:
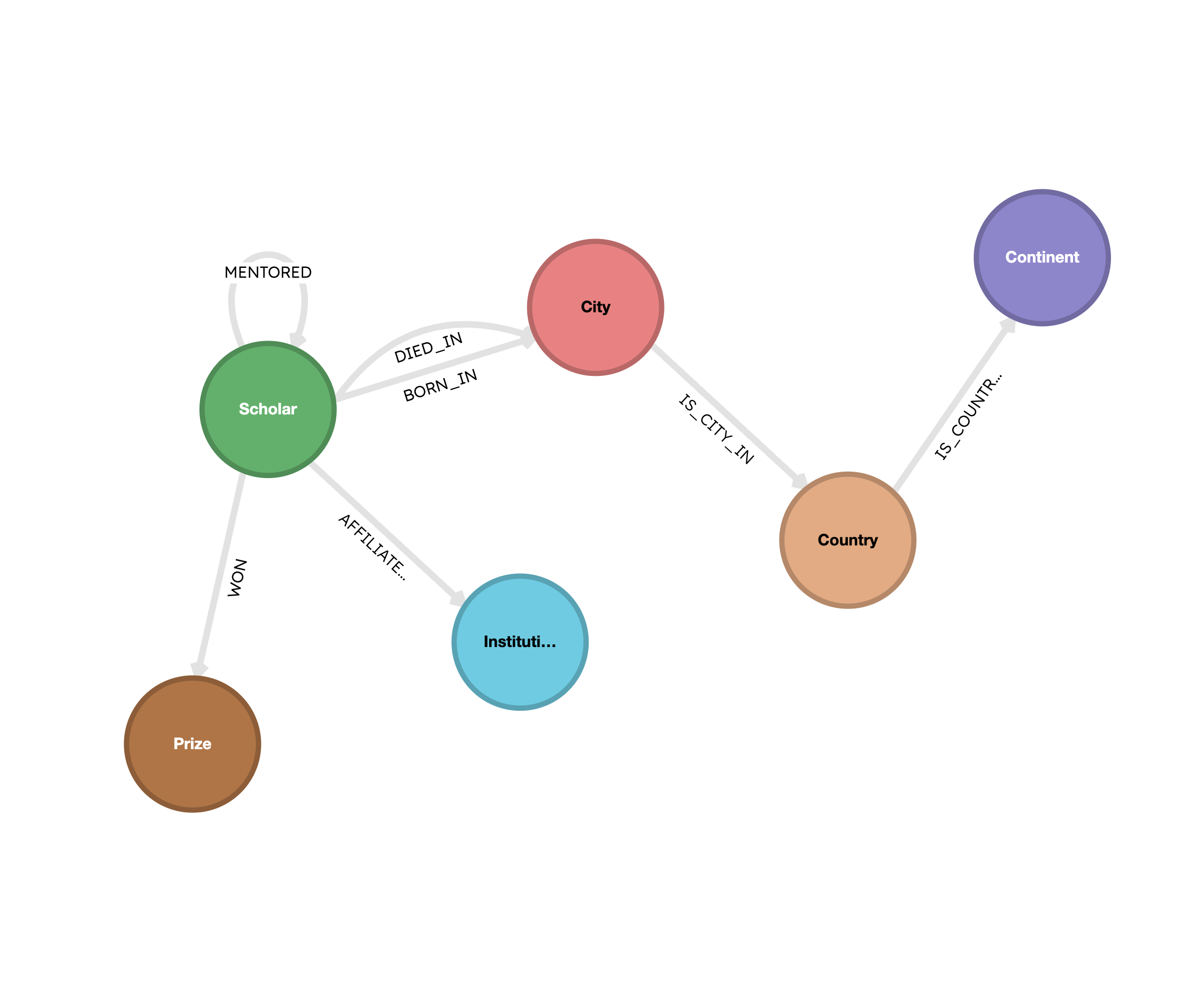
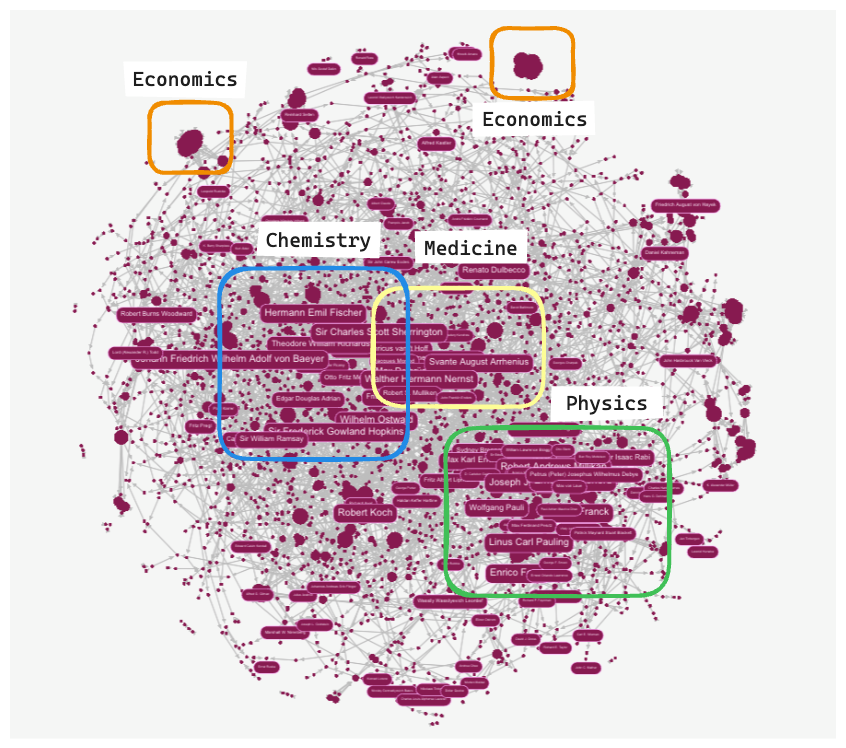
Below, we show a visualization of the full graph in G.V()3, where you can conveniently size the nodes by their out-degree (number of children) — larger nodes indicate that the scholar mentored more people. The image shows that many of these scholars in the early 20th century had an influence across multiple disciplines, with the physics, chemistry, and medicine clusters sharing many common connections. The economics clusters are more isolated, which makes sense because the field is relatively recent, and is more or less distinct from the pure sciences.
Cost implications
Below, we summarize some key numbers from the DSPy and graph construction pipeline.
| Metric | Value |
|---|---|
| Cost of end-to-end-DSPy pipeline | $0.07 |
| Run time of DSPy (async) pipeline | < 1 minute |
| No. of unique laureates | 655 |
| No. of mentorship relationships | 5,713 |
| No. of scholars (with or without Nobel prizes) | 2,726 |
| No. of Nobel prizes (awarded between 1901-2021) | 739 |
| No. of institutions | 345 |
| No. of cities | 194 |
| No. of countries | 57 |
| No. of continents | 6 |
For a mid-tier LLM like google/gemini-2.0-flash, the cost of running the DSPy pipeline
is less than 10 cents, and the entire pipeline runs in under a minute. The takeaway is this:
As LLMs continue to improve and
become faster and cheaper at the same time, it’s increasingly feasible to use them for
tasks like this that may have previously required combining supervised machine learning and
rule-based approaches. Of course, the more widespread the use of LLMs becomes, the more important
the evaluation, governance and safety aspects also become, but that’s a topic for another day.
Analyze the graph
With the entire data stored in Kuzu, we can now run Cypher queries to answer some interesting questions!
“How many Nobel laureates were descendants of Lord Rayleigh?“
// Lord Rayleigh has the id "l8" after data merging
// We run a recursive Cypher query using the Kleene star operator
MATCH (a:Scholar)-[:MENTORED*]->(b)
WHERE a.id = "l8"
AND b.scholar_type = "scholar"
RETURN count(DISTINCT b) AS num_descendants| value | value |
|---|---|
| num_descendants | 249 |
Lord Rayleigh4, one of the earliest Physics laureates, has a whopping 249 descendants who are themselves Nobel laureates! This implies that there are very dense interconnected clusters among the early Physics laureates.
Who are the female Chemistry Nobel laureates affiliated with non-US institutions?
// Multi-predicate, multi-path finding query
MATCH (s:Scholar)-[:WON]->(p:Prize),
(s)-[:AFFILIATED_WITH]->(i:Institution)-[:IS_LOCATED_IN]->(city:City)-[:IS_CITY_IN]->(country:Country)
WHERE s.scholar_type = "laureate"
AND s.gender = "female"
AND p.category = "chemistry"
AND country.name <> "USA"
RETURN DISTINCT s.knownName, city.name, country.name, i.name| s.knownName | city.name | country.name | i.name |
|---|---|---|---|
| Ada E. Yonath | Rehovot | Israel | Weizmann Institute of Science |
| Dorothy Crowfoot Hodgkin | Oxford | United Kingdom | University of Oxford, Royal Society |
| Emmanuelle Charpentier | Berlin | Germany | Max Planck Unit for the Science of Pathogens |
| Marie Curie | Paris | France | Sorbonne University |
There were four female laureates in Chemistry who were affiliated with non-US institutions — this is a question that required the enriched data to answer appropriately.
A lot more queries that combine insights from scholars, prizes and the institutions, cities, and countries they are affiliated with can be run in this manner. We’ll leave a more detailed exploration that uses graph algorithms and more, for a future post.
Conclusions
In this post, we discussed the task of data enrichment, and how it can be reformulated as a two-stage process involving vector search and LLM-as-a-judge for entity disambiguation. We introduced DSPy, a declarative AI framework, and showed how it can be easily plugged into existing data and LLM pipelines. In just a few lines of code, we were able to concisely incorporate DSPy’s core primitives into our pipeline, without writing a single prompt by hand. This opens up a powerful new way to work with LLMs, where you can focus on describing your intent rather getting caught up in the intricate details of how to properly phrase the prompt.
Of course, we could just as well have worked with LLMs using any other framework (e.g., BAML, as we’ve shown in an earlier post, or a raw LLM API call). However, the methodology we presented (and the reason we chose DSPy) is because it’s actually quite general-purpose and flexible enough to be applied in several other domains and tasks. It’s also scalable from a cost and performance perspective, because transforming a DSPy pipeline from sync to async involves just a few lines of code changes, and the vector search functionality in Kuzu can provide near-instantaneous retrieval results on very large datasets.
The approach shown here just scratches the surface of what’s possible with DSPy. In future posts, we’ll explore more advanced use cases, defining custom DSPy modules and adapters, plus adding evaluations and optimizers for graph-related tasks like Text2Cypher, information extraction, and more. Hopefully, this post got you curious to learn more.
You can check out the code and data to reproduce this entire workflow here. Stay tuned for more, star Kuzu on GitHub, and reach out to us on Discord, or on X, to share your thoughts! 🚀
Footnotes
-
The primary data source in this post is from the study “Nobel begets Nobel” by Richard S.J. Tol, which analyzes the proximity of the professor-student network for laureates and candidates in the field of economics. Interestingly, the study found that being a student or a grand-student of a Nobel laureate made the candidate significantly less likely to win a Nobel Prize. ↩ ↩2
-
Check out this Nature article on How to win a Nobel Prize for an interesting exploration of a similar nature (pun intended). ↩
-
All graph visualizations in this post are done using G.V(), a visualization tool for graphs that seamlessly connects to Kuzu databases. The nice thing about using G.V() is that you can display the entire graph in one go — it can easily handle up to thousands of nodes and tens of thousands of edges without any performance issues. This is thanks to its WebGL-powered rendering engine, which makes much more efficient use of your device’s computing power than traditional graph visualization tools that use SVG or Canvas. ↩ ↩2
-
You may remember the name “Lord Rayleigh” from high school physics — he provided an explanation of the scattering of light that causes the sky to appear blue — but his real name was John William Strutt. Lord Rayleigh was his title and not his name. If you look at the interactive results from footnote #2 (the Nature article), you’ll see that Lord Rayleigh trained only one laureate himself (J.J. Thomson), but J.J. Thomson, with 11 laureates as his descendants, really got the tree going. This led to a total of 200+ descendants originating from the tree with Rayleigh as the root node. These kinds of queries can be asked very naturally and easily in Cypher, the query language of Kuzu. ↩ ↩2
-
As in many other scenarios, an LLM’s outputs are probabilistic in nature. So for mission-critical applications, you may want to have a human-in-the-loop or use a dedicated SDK like Senzing to handle entity disambiguation and resolution tasks. It’s always important to do adequate due diligence, testing and evals before deploying any LLM-based pipeline in production. ↩
-
You can also use the
dspy.ChainOfThoughtmodule in case you’re using a smaller model or the task is slightly more complex. Allowing the model to reason over its chain of thought can significantly improve the quality of the output, but it also takes longer and requires more tokens. ↩