

RAG using unstructured data and the role of knowledge graphs

CEO of Kùzu Inc. & Associate Prof. at UWaterloo
In my previous post, I gave an overview of question answering (Q&A) systems that use LLMs over private enterprise data. I covered the architectures of these systems, the common tools developers use to build these systems when the enterprise data used is structured, i.e., data exists as records stored in some DBMS, relational or graph. I was referring to these systems as RAG systems using structured data. In this post, I cover RAG systems that use unstructured data, such as text files, pdf documents, or internal html pages in an enterprise. I will refer to these as RAG-U systems or sometimes simply as RAG-U (should have used the term RAG-S in the previous post!).
To remind readers, I decided to write these two posts after doing a lot of reading in the space to understand the role of knowledge graph (KGs) and graph DBMSs in LLM applications. My goals are (i) to overview the field to readers who want to get started but are intimidated by the area; and (ii) point to several future work directions that I find important.1
TL;DR: The key takeaways from this post are:
- Two design decisions when preparing a RAG-U system are (i) “What additional data” to put in prompts; and (ii) “How to store and fetch” the additional data.: Explored options for types of additional data include chunks of texts, full documents, or automatically extracted triples from documents. There are different ways to store and fetch this additional data, such as use of vector indices. Many combinations of this design space are not yet explored.
- Standard RAG-U: A common design point, which I will call the standard RAG-U, is to add chunks of documents as additional data and store them in a vector index. I found some of the most technically deep and interesting future work directions in this space, e.g., extending vectors to matrices.
- An envisioned role for KGs in a RAG-U system is as a means to link chunks of text: If chunks can be linked to entities in an existing KG, then one can connect chunks to each other through the relationships in KG. These connections can be exploited to retrieve more relevant chunks. This is a promising direction but its potential benefits should be subjected to rigorous evaluation, e.g., as major SIGIR publications evaluate a new retrieval technique. It won’t pick up through commercial blog posts.
- What if an enterprise does not have a KG? The hope of using KGs to do better retrieval in absence of a pre-existing KG raises the question and never ending quest of automatic knowledge graph construction. This is a very interesting topic and most recent research here uses LLMs for this purpose but: (i) LLMs seem behind in extracting quality knowledge graph facts; and (ii) it’s not clear if use of LLMs for this purpose at scale is economically feasible.
RAG-U Overview
I will skip the overview of RAG systems, which I covered in the previous post. The picture of RAG systems that use unstructured data looks as follows:
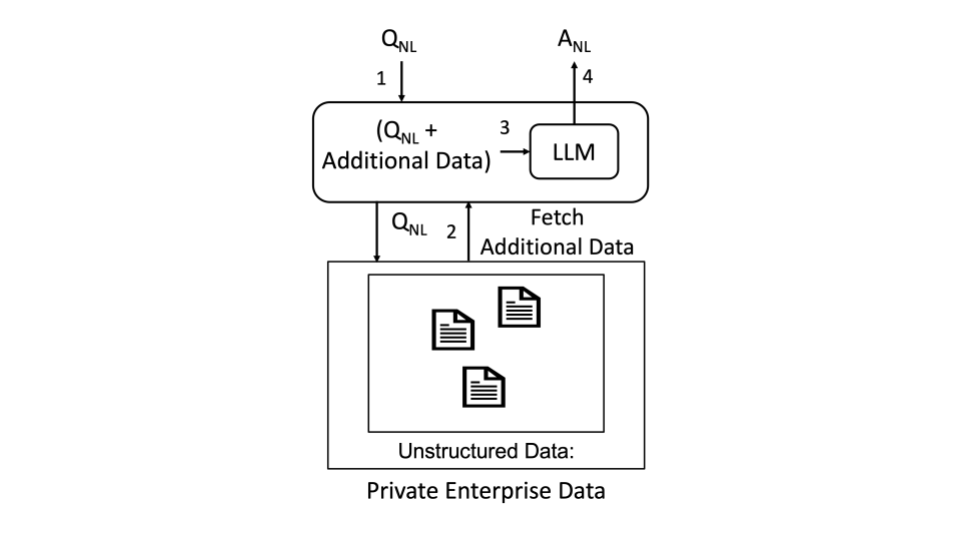
An enterprise has a corpus of unstructured data, i.e., some documents with text. As a preprocessing step (omitted from the figure), the information in these documents are indexed and stored in some storage system. The figure labels the 4 overall steps in a RAG-U system:
- A natural language query comes into the RAG-U system.
- Parts of the corpus of unstructured data that is expected to be helpful in answering is fetched from some storage system.
- The fetched data along with given to an LLM.
- LLM produces a natural language answer for .
Any system built along these 4 high-level steps needs to make two design choices:
Design Choice 1: What is the additional data? Among the posts, documentation, and demonstrations I have read, I have seen three designs:
- Chunks of documents
- Entire documents
- Triples extracted from documents
Design Choice 2: How to store and fetch the additional data? Here, I have seen the following designs:
- Vector Index
- Vector Index + Knowledge Graph (stored in a GDBMS)
- GDBMS (for storing triples)
Many combinations of these two choices are possible and can be tried. Each choice can effectively be understood as a retrieval heuristic to fetch quality content that can help LLMs answer more accurately. I will cover a few of the ones that I have seen but others are certainly possible and should be tried by people developing RAG-U systems.
Standard RAG-U: Chunks of Documents Stored in a Vector Index
Standard RAG-U is what you will read about in most places. Its design is as follows: (i) we split the text in the documents into (possibly overlapping) “chunks”; (ii) we embed these chunks into vectors, i.e., high dimensional points, using a text embedding model (many off-the-shelf open-source models exist from OpenAI, Cohere, and Hugging Face); and (iii) we store these vectors in a vector index. For example, see LangChain main documentation on “Q&A with RAG” or LlamaIndex’s “Building a RAG from Scratch” documentation. The below figure shows the pre-processing and indexing steps of standard RAG-U:

First a note on vector indices: A vector index is one that indexes a set of d-dimensional vectors and given a query vector w can answer several queries: (i) pure search: does w exist in the index?; (ii) k nearest neighbors: return the k vectors closest to w; or (iii) range queries: return vectors that are within a radius r of w. There have been decades of work on this topic. If d is very small, say 3 or 4, there are “exact spatial indices” like quad trees (for 2D only), r-trees, or k-d trees. These indices have good construction and query times when d is small but their performance degrades fast when d increases and they quickly become impractical. There have been some good work to index high-dimensional vectors as well. SA-trees by Navarro is the core technique that underlies the nowadays popular indices, such as hierarchical navigable small-world graph (HNSW) indices, which are extensions of navigable small world (NSW) indices. Navarro’s SA-tree index returns exact results as well2 but does not have good query times. In Navarro’s experiments, even for relatively small dimensions such as 10-20, sa-tree can scan 10-100% of all vectors in the index for queries that need to return less than 1% of the vectors. SNW and HSNW instead are not exact indices. They are called approximate indices but they are not even approximate in the sense of having any approximation guarantees in their query results. They are heuristic-based indices that can index very high-dimensional vector and are fast both in their construction and their query times. Further, their query results are shown to be quite accurate empirically. HNSW indices are nowadays used by vector databases like Pinecone and Weaviate or search engine libraries such as Lucene in their vector indices. To understand these indices, I highly suggest first reading the Navarro paper paper, which is the foundation. It’s also a great example of a well-written database paper: one that makes a very clear contribution and is explained in a very clean technical language.
Back to RAG-U. After the preprocessing step, the vector index that contains the chunks of documents is used in a RAG-U system as follows:
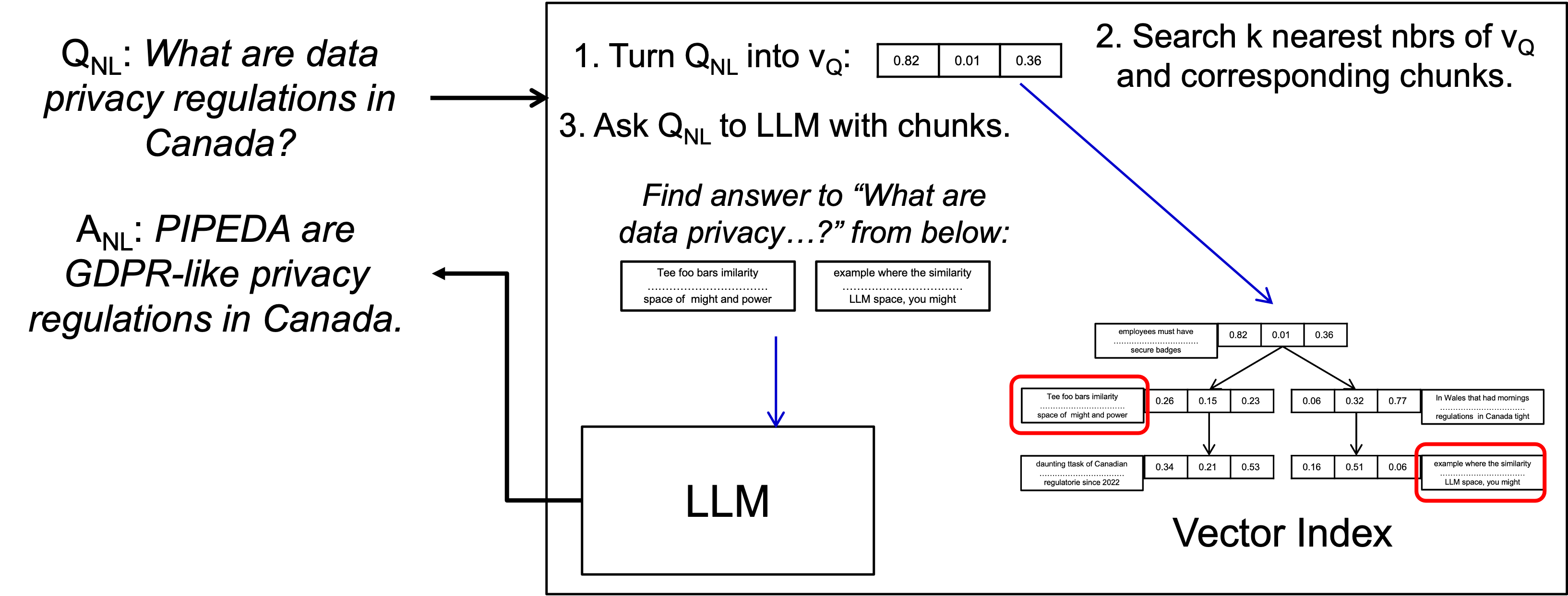
The step are as follows: (i) The question is first embedded into the same d-dimensional vector space as the chunks were. Let’s call this vector ; (ii) k nearest neighbors of are searched in the vector index (for some value of k) ; and (iii) the chunks that correspond to are retrieved (in the figure above, these are the chunks in red boxes) and put into the LLM prompt along with . The hope is that the chunks whose vector representation were close to contain useful information for the LLM to answer . In practice there could be more steps to rank those chunks and maybe select a fewer number of them to give to the LLM.
Overall, my reading on standard RAG-U was quite technically deep. That’s not surprising since the success of these pipelines depend on two core technical problems:
- How “good” are the embeddings that are inserted into the vector index, i.e., how well does it capture the relatedness of to the chunks. This is a core problem in the neural IR.
- How accurate is the vector index in finding top-k nearest neighbors to the vector embedding of . This is a core database problem.
Important Future Work 1: I believe we should be seeing more exciting work coming up in this space. One topic is the use of matrices instead of vectors to embed chunks and questions. This is done in the ColBERT-style “neural retrieval models” that are shown to work well on some Q&A benchmarks. Indexing and retrieval of these matrices is an interesting topic and I have even seen some off-the-shelf tools, e.g., the RAGatouille package of LlamaIndex, that allows developers to replace the vectors in the standard RAG-U figure above with matrices. Tons of good future work is possible in this space from improving the accuracy and efficiency of the vector/matrix indices to the evaluation of RAG-U systems that use these vectors.
First Envisioned Role of Knowledge Graphs in RAG-U: Explicitly Linking Chunks
One limitation of standard RAG-U is that the chunks are treated as isolated pieces of text. To address this problem, several posts that I read (1, 2) envision linking these chunks to each other using a KG (or another form of graph). Compared to standard RAG-U, the design choice for “what additional data” is still document chunks but “how to fetch” is different and it is a mix of vector index + a KG stored in a GDBMS. The preprocessing over standard RAG-U (see the preprocessing figure above) would be enhanced with an additional step as follows:
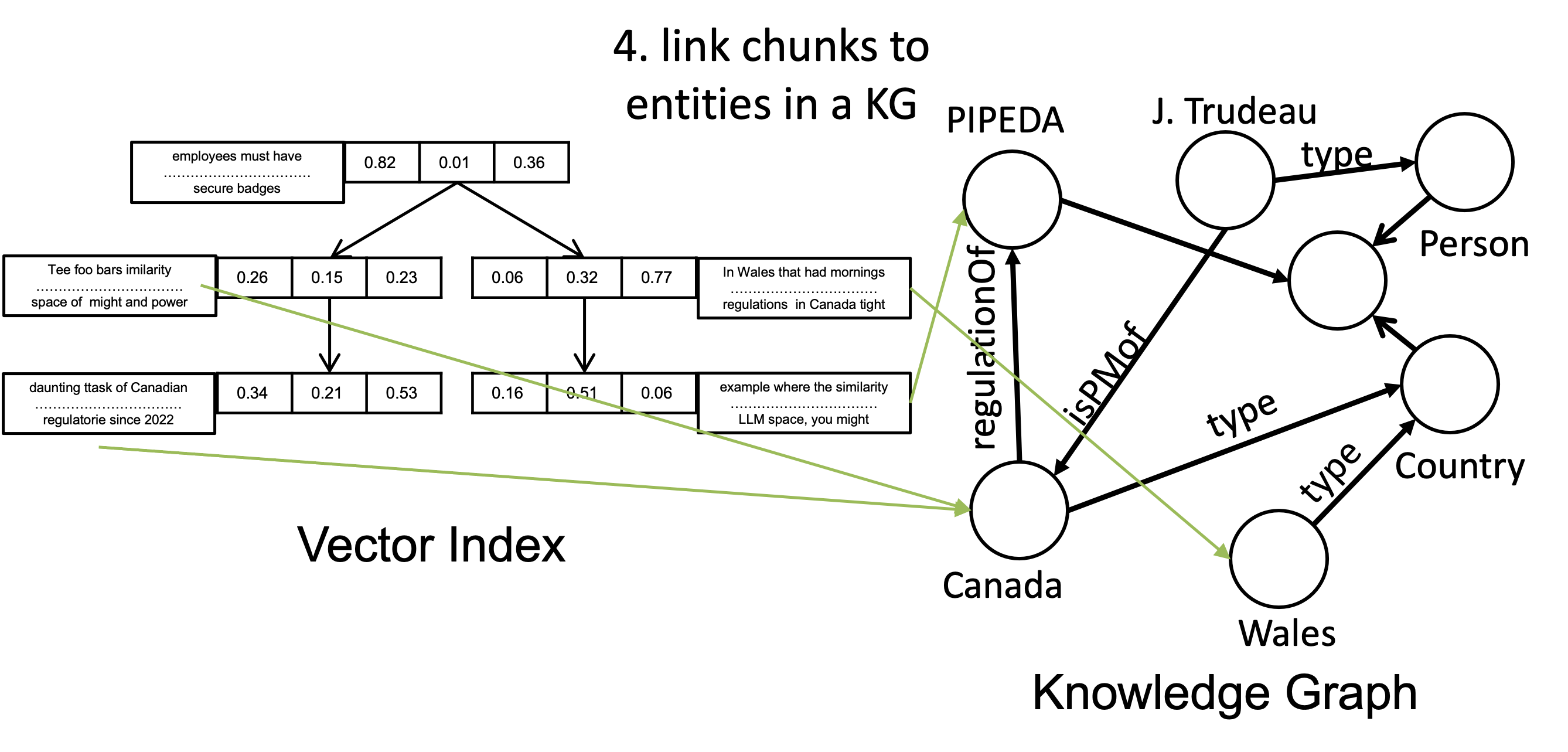
That is, using some entity extraction mechanism, the chunks would be linked to the entities that they mention in the KG (assuming the KG contains these entities as nodes). You can think of this linking as adding new edges to the KG that relate entities to some chunkIDs that identify the chunks in the vector index. After the preprocessing step, the standard RAG-U system would be enhanced as follows:

Similar to standard RAG-U, we have a vector index and additionally a KG, say stored in a GDBMS. As before is embedded into a vector , whose k nearest neighbors and their corresponding chunks are found in the vector index. Then, the system extracts additional chunks based on some graph traversal heuristic. A simple heuristic is to traverse from the to all entities, say {, , …, }, that are mentioned in . Then, we can optionally explore the neighborhood of these entities to extract other entities, say {, …, , , …, }, where to are the new entities extracted. Then, we further find other chunks that mention these entities. In the figure above I’m simulating this by having a third red box that was not retrieved in the standard RAG-U figure. Now through another ranking, we can obtain another top-k chunks amongst this new set of chunks and put them into the prompt.
This vision is interesting and several prior papers also hint at similar related use of KGs in Q&A applications. The most interesting paper I read that’s related to this approach was this ACL 2019 paper. This paper pre-dates the current LLMs and is not about RAG. Instead, it maps the entities mentioned in a question to entities in a KG, and then extracts the subgraph of relations between these entities from the KG. Then, the relations and entities in this subgraph are used as possible answers to the question (in some sense, this is also a form of RAG). The paper’s approach does not connect the chunks but connects the entities in the question using a KG. Overall, I think the idea of linking chunks through the entities that they mention is promising and I want to identify three important future work here that can push this approach forward.
Important Future Work 2: This approach assumes that the enterprise already has a knowledge graph. Although I am a strong believer that enterprises should invest in the construction of clean enterprise-level KGs with well defined and consistent vocabularies, in practice many enterprises do not have readily-available KGs. Therefore the use of this style of KG-enhanced RAG-U approaches rely on tools that can generate KGs. This is a never ending quest in academic circles and I’ll say more about this below (see “Important Future Work 5”).
Important Future Work 3: The graph heuristic I described above to extract further chunks is only one that can be explored amongst many others. For example, one can map the entities in the question to nodes in the KG, find shortest paths between them, and retrieve the chunks that mention the nodes/entities on these paths. These variants need to be systematically evaluated to optimize this approach.
Important Future Work 4: Although variants of this approach, such as the ACL paper I mentioned have a lot of technical depth and rigorous evaluations, this approach so far appears only in blog posts which don’t present an in-depth study. This approach needs to be subjected to a rigorous evaluation on Q&A benchmarks.
Second Envisioned Role of Knowledge Graphs in RAG-U: Extracting Triples Out of Chunks
In the LlamaIndex KnowledgeGraphIndex package, there is one more usage of KGs in RAG-U applications. In this approach, the answer to the “what additional data” question is “triples extracted from the unstructured documents”. The answer to the “how to fetch” question is to do a retrieval of these triples from a GDBMS. Here is the preprocessing step:

Using some triple extraction, the unstructured document is pre-processed to generate a KG. I will discuss this step further but overall you can use either a triple extraction model, such as REBEL or another model, or an LLM directly. Both can be used off-the-shelf. Then, these triples, which form a KG, are stored in a GDBMS and used in RAG in some form. I’m giving one example approach below but others are possible. The approach I will show is implemented in the examples used in LlamaIndex’s documentations using LlamaIndex KnowledgeGraphIndex:
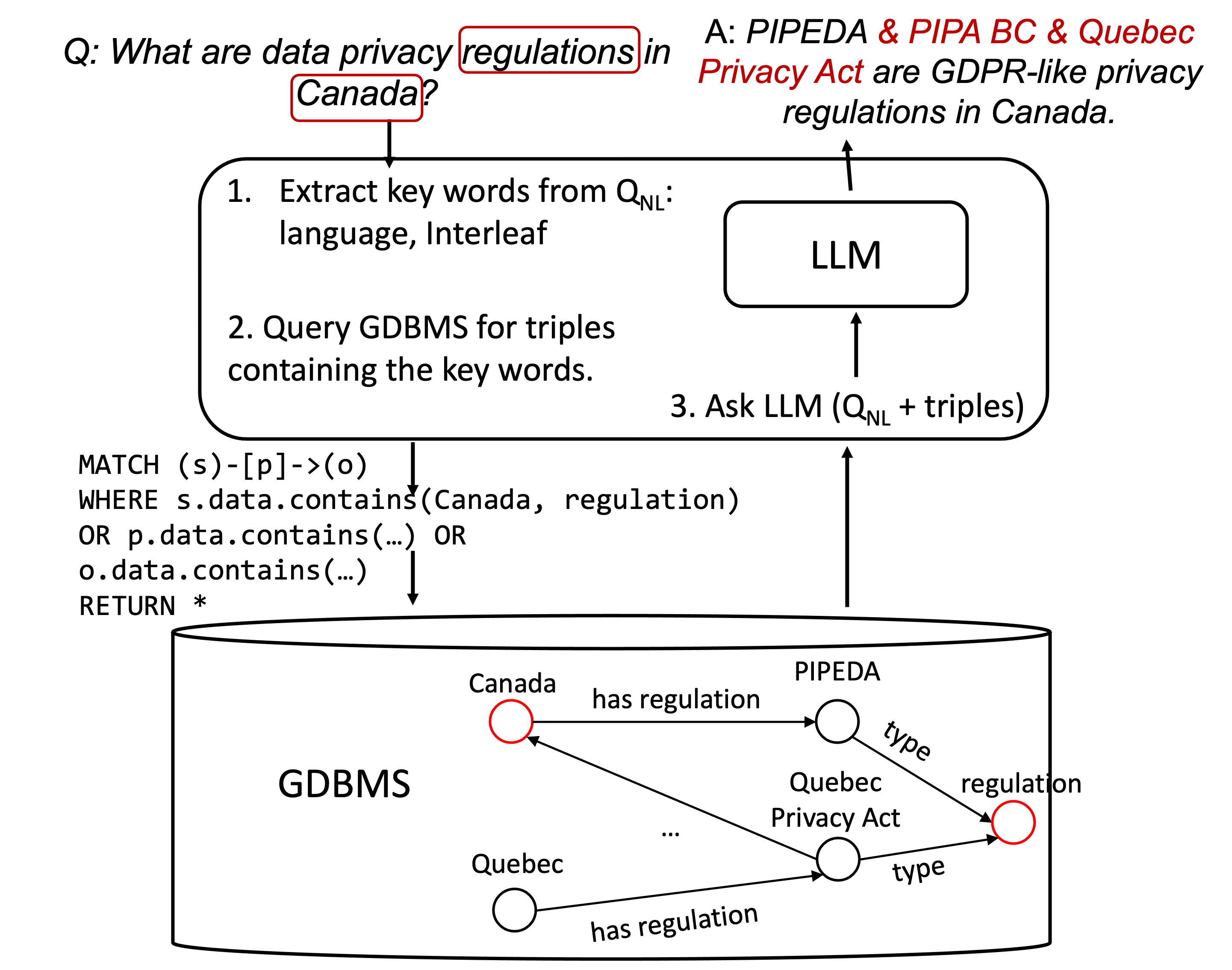
The triples are stored in a GDBMS. You can use a LlamaIndex GraphStore for this and Kuzu has an implementation; see the KuzuGraphStore demo here. The system extract entities using , using some
entity or keyword extractor. In the LlamaIndex demos, this is done by using an LLM. Specifically,
LLM is prompted with the following prompt: A question is provided below. Given the question, extract up to {max_keywords} keywords from the text.... etc. These keywords are used
to extract triples from the GDBMS by using them in the query sent to the GDBMS as shown in the above figure.
Finally the returned triples are given to the LLM prompt as additional data to help answer .
LlamaIndex offer other ways to extract these triples that are also readily available to use. For example, you can embed these triples into vectors and use a vector index to fetch them. So although the final additional data is still triples, how they’re fetched is through a vector index and not a GDBMS. Other options are also possible.
I want to make three points here. First, notice that extracting triples also provides a means to link the text in the unstructured text, which was a shortcoming I had highlighted in standard RAG-U. Second, by putting triples into prompts instead of chunks, you are also probably saving the tokens you are using in your LLM applications. That’s because triples are like summaries of the statements in more verbose sentences in chunks. Third, the success of such RAG applications depends on the quality of the triples extracted in the pre-processing step, which is the next future work direction I want to highlight:
Important Future Work 5: The success of RAG-U applications that use triples or the KG-enhanced standard RAG-U applications depend on the availability of a technology that can automatically extract knowledge graphs from unstructured documents.
This is a fascinating topic and is a never ending quest in research. Here is an extensive survey with 358 citations that scared me so I decided to skip it. But my point is that this has been a never ending research topic. The most recent work I see here is on using LLMs for this task. I can recommend these two papers here: 1 and 2. General conclusions so far are that LLMs are not yet competitive with specialized models on extracting high quality triples. We’ll see how far they will go. Surprisingly, a very important question for which I could not find much to read on is this:
Important Future Work 6: How economical would be the use of LLMs to extract KGs at scale (when they’re competitive with specialized methods)?
So could we ever dream of using LLMs to extract billions of triples from a large corpus of unstructured documents? Probably not if you’re using OpenAI APIs, as it would be painfully expensive, or even if you’re running your own model, as it would be excruciatingly slow. So I am a bit pessimistic here. My instinct is that you might be able to generate KGs from unstructured documents using the slightly older techniques like designing your own models or using extractor-based approaches like DeepDive3 and SpanMarker4. I know it’s not exciting to not use LLMs, but you’re likely to extract much higher quality triples and much more cheaply with specialized models. So I don’t know who really thinks it could one day be a good idea to use LLMs to extract triples from large corpuses.
Agents: Developing RAG Systems That Use Both Structured & Unstructured Data
Let me now start wrapping up. In my last post and this one, I covered RAG systems using structured and unstructured data. There are several tools you can use to develop RAG systems that retrieve data from both structured records or one that conditionally retrieves from one or the other. LangChain Agents and LlamaIndex Agents make it easy to develop such pipelines. You can for example instruct the “Agent” to take one of two actions conditionally as follows: “if the question is about counting or aggregations retrieve records from the GDBMS by converting to a Cypher query; otherwise follow the RAG-U pipeline to retrieve chunks from documents.” These are essentially tools to develop a control logic over your LLM applications. It reminds me of the good old days when there was a crazy hype around MapReduce-like “big data systems” and several initial works, such as Pig Latin and Ciel, immediately were addressing how to develop libraries/languages over these systems to implement advanced control flows. Agents, or the recent LangGraph, seem like initial answers to the question of “how do you program advanced LLM applications?”
Final Words
I want to conclude with two final points. First, there are many other applications that can use LLMs and KGs beyond Q&A. I don’t have space to cover them here. Here is a survey paper that attempts to organize the work in this space. The topics vary from how KGs can be used to train better LLMs to how LLMs can be used to construct KGs to how one could embed both text and KG triples together as vectors to better train LLMs.
Second, I listed 3 possible answers for the “what additional data” design decision and 3 possible answers for “how to fetch” design decision. I further mentioned different graph-based heuristics to extract chunks (or triples) once you can link the information in the unstructured documents to each other through a KG. Many combinations of these design decisions and many other graph heuristics are not yet explored. So there is quite a lot to explore in this space. The overall impression I was left with was that we need more technically deep material in the space, which will only come through rigorous evaluations of these RAG systems on standard benchmarks, as done in SIGIR or ACL publications. I went through SIGIR 2023 publications and did not find work on a Q&A system that uses LLMs + KGs similar to the approaches I covered here. I hope to see such papers in 2024.
Footnotes
-
In this post I’m only covering approaches that ultimately use retrieve some unstructured data (or a transformation of it) to put it into LLM prompts. I am not covering approaches that query a pre-existing KG directly and use the records in it as additional data into a prompt. See this post by Ben Lorica for an example. The 3 point bullet point after the “Knowledge graphs significantly enhance RAG models” describes such an approach. According to my organization of RAG approaches, such approaches would fall under RAG using structured data, since KGs are structured records. ↩
-
The term sa-tree stands for “spatial approximation”, which refers to the following fact. Exact spatial indices like kd-trees are balanced and divide a d-dimensional space into “equal” sub-spaces (not in volume but in the number of vectors that are contained in the sub-spaces). Instead, sa-trees divide the space approximately and are not necessarily balanced but sa-trees return exact answers. ↩
-
In DeepDive, you would write extractors for the type of triples you wanted to extract manually and DeepDive would use them in combination as part of a model to extract high quality triples. Or you can just default to thinking hard about what you want to extract, so what type of questions you want to answer in your RAG system, and based on those give example documents and triples and train a specialized model. ↩
-
SpanMarker is a recent approach for training powerful Named Entity Recognition models and is tightly implemented on top of the Transformers library by Hugging Face. It is based on the PL-Marker paper. The idea is to train a model that can detect NER entities from a large corpus of documents., label them with their types and map these types to the required triples as per your business domain. ↩