

RAG using structured data: Overview & important questions

CEO of Kùzu Inc. & Associate Prof. at UWaterloo
During the holiday season, I did some reading on LLMs and specifically on the techniques that use LLMs together with graph databases and knowledge graphs. If you are new to the area like me, the amount of activity on this topic on social media as well as in research publications may have intimidated you. If so, you’re exactly my target audience for this new blog post series I am starting.
My goals are two-fold:
-
Overview the area: I want to present what I learned with a simple and consistent terminology and at a more technical depth than you might find in other blog posts. I am aiming a depth similar to what I aim when preparing a lecture. I will link to many quality and technically satisfying pieces of content (mainly papers since the area is very researchy).
-
Overview important future work: I want to cover several important future works in the space. I don’t necessarily mean work for research contributions but also simple approaches to experiment with if you are building question answering (Q&A) applications using LLMs and graph technology.
This post covers the topic of retrieval augmented generation (RAG) using structured data. Then, in a follow up post, I will cover RAG using unstructured data, where I will also mention a few ways people are building RAG-based Q&A systems that use both structured and unstructured data.
TL;DR: The key takeaways from this post are:
- RAG overview: RAG is a technique to fill the knowledge gap of LLMs using private data. RAG systems use private structured records stored in a database and/or unstructured data in text files.
- Impressive simplicity and effectiveness of developing a natural language interface over your database using LLMs: In the pre-LLM era, the amount of engineering effort to develop a pipeline that delivered a natural language interface over your database was immense. The hard problem was to teach a model to speak SQL, Cypher, or SPARQL. This contrasts sharply with the simplicity of developing similar pipelines now because LLMs already “speak” these languages. The hard task now is for developers to learn how to prompt LLMs to get correct database queries. Furthermore, there is evidence that LLMs, if prompted correctly, will generate a decent proportion of queries with impressive accuracy.
- Lack of work that studies LLMs’ ability to generate Cypher or SPARQL: Most technically-deep work on understanding LLMs’ ability to generate accurate high-level query languages is on SQL. We need more work understanding the behavior of LLMs on the query languages of GDBMSs (like Cypher or SPARQL), specifically on recursive and union-of-join queries.
- Studying the effects of data modeling (normalization, views, graph modeling) on the accuracy of LLM-generated queries is important: Many people are studying heuristics for prompting LLMs to increase their efficiency focusing on the syntax and the structure of providing the schema and selection of examples in the prompt. An important and under-studied problem is the effects of data modeling choices on the accuracy of the queries generated by LLMs. I point to one interesting paper in this space and raise several questions related to normalizations and use of views in relational modeling and comparisons with graph modeling approaches.
Killer App: Retrieval Augmented Generation
Let’s review the killer application of LLMs in enterprises. The application is ultimately Q&A over private enterprise data. Think of a chatbot to which you can ask natural language questions (), such as: “Who is our top paying customer from Waterloo?”, or “What are data privacy regulations in Canada we need to comply with?” and get back natural language answers (). LLMs, out of the box, cannot answer these questions because they have a knowledge gap. For example, LLMs never had any access to your sales records when they were trained. Therefore, they need to retrieve or be provided with extra information from private data sources of the enterprise.
A note on the term RAG
There seems to be tremendous interest in building systems that combine a traditional information retrieval component, e.g., one that looks up some documents from an index, with a natural language generator component, such as an LLM. The term for such systems is Retrieval Augmented Generation (RAG). The term is coined in this paper to refer to the method of fine-tuning an LLM with additional information, i.e., using this additional data to train a new variant of the LLM. The original usage form in the paper is “RAG models”. Nowadays it is used in a variety of ways, such as, “RAG system”, “RAG-based system”, “RAG does X”, or “Building RAG with Y”. RAG often does not refer to fine-tuning LLMs any more. Instead, it refers to providing LLMs with private data along with the question to fix the knowledge gap. Even systems that simply use an LLM to convert a to SQL or Cypher query and simply return the results of the query are called “RAG systems” in some documentations. I will use the term in this broader sense.
You can build RAG-based Q&A systems by using structured and/or unstructured data. The high-level views of these systems look like this:
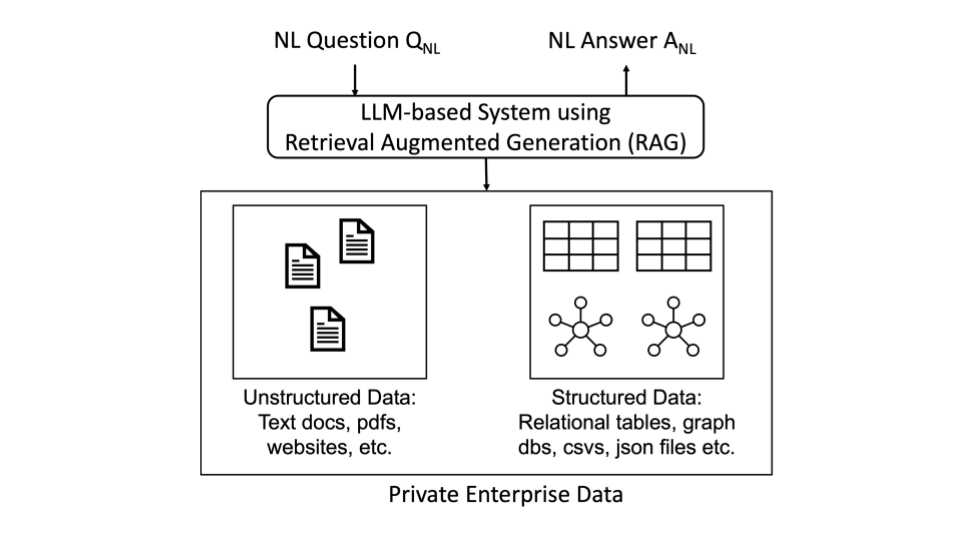
RAG Using Structured Data: Text-to-High-level-Query
Note: If you are familiar with how to develop RAG systems with LangChain and LlamaIndex, you can directly skip to the ”How Good are LLMs in Generating High-level Queries” part that reflects on the reading I did on RAG using structured data.
Overview
Many blog posts and several papers concern Q&A systems that simply convert to a high-level query languge, such as SQL, Cypher, or SPARQL, using an LLM. The figure below describes the overall approach:
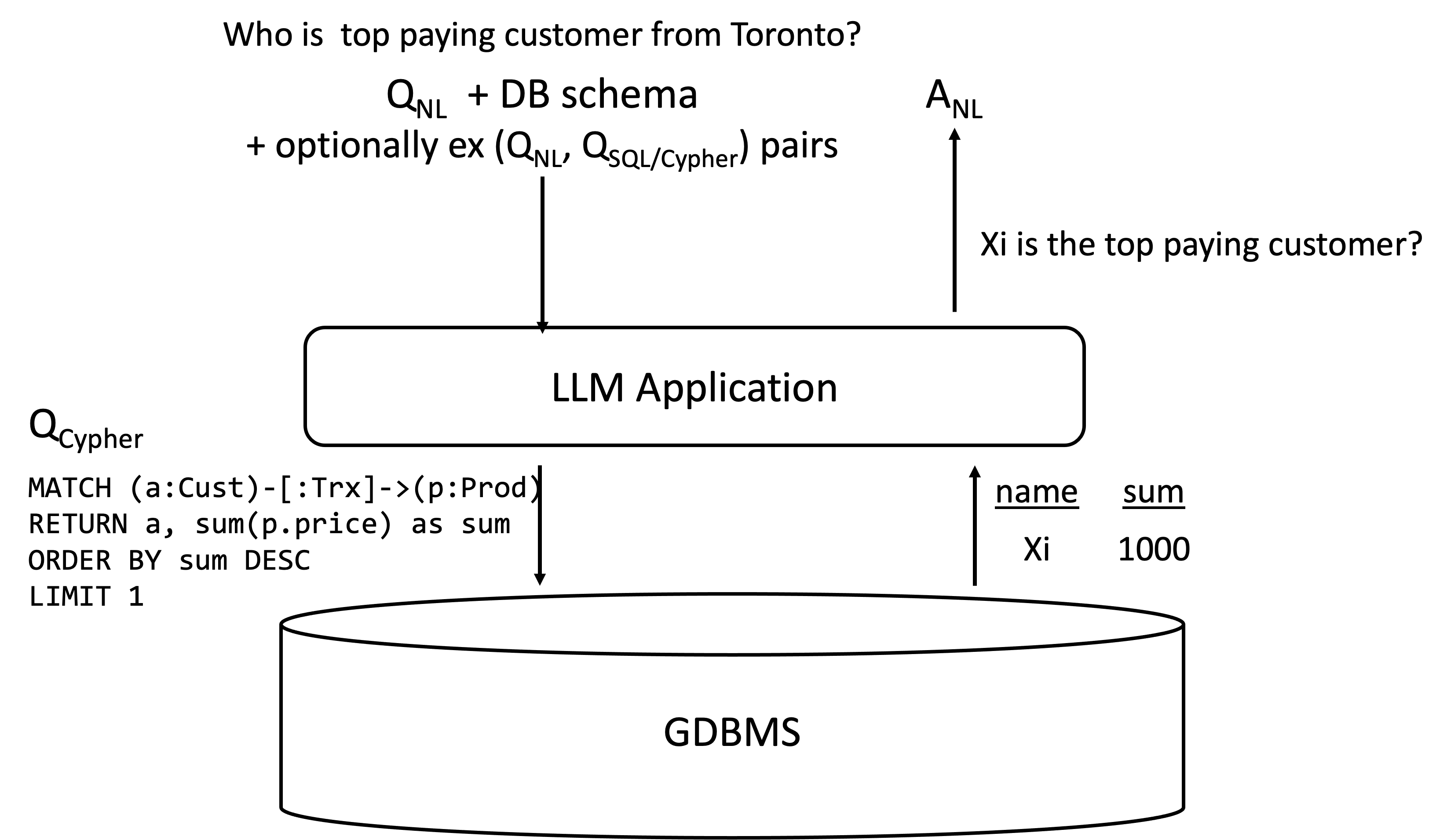
, the schema of a database, and optionally some example natural language question and high-level query examples, are given to the LLM as a prompt. The terms “no shot”, “one shot”, or “few shot” refer to the number of examples provided in the prompt. Depending on the underlying database, the schema may contain columns of relational tables and their descriptions, or labels of nodes and edges of a graph database. Using , the database schema, and optionally some examples, the LLM generates a database query, such as SQL or Cypher. The system runs this query against the DBMS and returns back the query result or using the LLM again, converts the query result back to a natural language answer .
Let us pause here to appreciate one thing: For many decades, the database community has studied the problem of converting to SQL (aka “text-to-SQL”). Here is a good recent survey paper that covers only the deep network-based approaches and a more extensive survey/book on the broader topic of natural language interfaces to databases. Neither of these surveys cover any work that directly uses LLMs such as GPT models, which are quite recent developments. Take any of the work covered in these surveys and you’ll find an approach that requires significant engineering to build the pipeline shown in the above figure. There exist several pre-LLM text-to-SQL systems, such as ATHENA or BELA. Most of the pre-LLM approaches that use deep learning require hard work to teach a model how to “speak” SQL using large corpora of tables and (question, query) examples, such as WikiSQL or Spider. People had to solve and glue-together solutions to many technical problems, such as parsing the question, entity detection, synonym finding, string similarity, among others. Post-LLM approaches require none of these efforts because LLMs, such as GPT-4, already speak SQL, Cypher, and SPARQL out of the box, having been exposed to them in their pretraining. Nowadays, the hard problem now is for developers to learn how to prompt LLMs so that LLMs generate correct queries. I’ll say more about this problem. In contrast, building the above pipeline requires much less effort as I’ll show next.
Simplicity of Developing RAG Systems: LangChain and LlamaIndex
If you have been following the developments in the LLM space, you will not be surprised to hear that nowadays people build
Q&A systems that convert to a high-level query language using two common tools:
(i) LangChain; and (ii) LlamaIndex.
The same tools also integrate with the underlying storage system to load and retrieve your data. To make this more concrete, let me review the Kùzu-LangChain integration, which is similar to the integrations of other GDBMSs. You as a programmer have very little to do: you prepare your Kùzu
database db and load your data into it, wrap it around a KuzuGraph and KuzuQAChain objects in Python and you have
a text-to-Cypher pipeline:
import kuzu
from langchain.chains import KuzuQAChain
from langchain_community.chat_models import ChatOpenAI
from langchain_community.graphs import KuzuGraph
db = kuzu.Database("test_db")
... // create your graph if needed
graph = KuzuGraph(db)
chain = KuzuQAChain.from_llm(ChatOpenAI(temperature=0), graph=graph, verbose=True)
chain.run("Who played in The Godfather: Part II?")I am following the example application in this documentation, which uses a database of movies, actors, and directors.
Output:
> Entering new chain...
Generated Cypher:
MATCH (p:Person)-[:ActedIn]->(m:Movie {name: 'The Godfather: Part II'}) RETURN p.name
Full Context:
[{'p.name': 'Al Pacino'}, {'p.name': 'Robert De Niro'}]
> Finished chain.
'Al Pacino and Robert De Niro both played in The Godfather: Part II.'The “chain” first generated a Cypher query using . Behind the curtain, i.e., inside the KuzuQAChain code, a GPT model was given the following prompt:
Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
Node properties: [{'properties': [('name', 'STRING')], 'label': 'Movie'}, {'properties': [('name', 'STRING'), ('birthDate', 'STRING')], 'label': 'Person'}]
Relationships properties: [{'properties': [], 'label': 'ActedIn'}]
Relationships: ['(:Person)-[:ActedIn]->(:Movie)']
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
Who played in The Godfather: Part II?Indeed, if you copy this prompt and paste it in chatGPT’s browser interface,
you will get the same or a very similar Cypher query. The important point is: that’s all
the coding you have to do to build a natural language interface that can query your database.
You ultimately construct a string prompt that contains , some
instructions, and schema of the database, and the LLM will generate a query for you.
The KuzuGraph and KuzuQAChain are simple wrappers to do just that.
If you want to play around with how well this works on other datasets,
we have this pipeline implemented in Kùzu’s browser frontend KùzuExplorer.
That is, for any database you have in Kùzu, you get a natural language interface over it in KùzuExplorer (just click the “robot icon” on the left panel). You can develop similar pipelines with other GDBMSs using similar interfaces (though I recommend using Kùzu as it will be the simplest to get started 😉: Unlike other GDBMSs, Kùzu is embeddable and requires no server set up). If you instead want to build Q&A systems over your RDBMSs, you can use LangChain’s SQLDatabaseChain and SQLAgent or LlamaIndex’s NLSQLTableQueryEngine. The level of simplicity is similar to the example I presented. In practice, it is unlikely that your chatbot or search engine will be as simple as the above example where the application interacts with the LLM only once. If you want to interact with the LLM multiple times and conditionally take one action over another action etc., LangChain and LlamaIndex also provide ways to do that through their “Agents” (see LangChain Agents and Llama Index Agents).
How Good Are LLMs in Generating High-Level Queries?
Although building a text-to-high-level-query-language pipeline is now very simple with LLMs, simplicity does not mean quality. Indeed, people building these systems are now faced with the following two important questions:
- How accurate are the high-level queries that LLMs generate?
- How, e.g., through what types of prompts or data modeling, can we increase the accuracy of the queries generated by LLMs?
Here are several papers on this that I suggest reading:
- A comprehensive evaluation of ChatGPT’s zero-shot Text-to-SQL capability from Tsinghua University and University of Illinois at Chicago.
- Evaluating the Text-to-SQL Capabilities of Large Language Models from researchers from Cambridge and universities and institutes from Montréal.
- Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation from Alibaba Group.
- Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies from Yale, Columbia, and Allen Institute for AI.
- How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings from Ohio State
- A Benchmark to Understand the Role of Knowledge Graphs on LLM’s Accuracy for Q&A on Enterprise SQL Databases from data.world.
These papers are either entirely or almost entirely evaluation-only papers that experiment with very detailed approaches of prompting LLMs to generate SQL queries. First, let me say that the general message these papers give (maybe except the last one) is that LLMs are pretty good. With right prompting (or even with basic prompting) they do very well on these benchmarks. I see accuracy rates over 85% on the Spider benchmark in several papers. These are clearly better numbers than what pre-LLM state-of-the-art systems achieved. This should be impressive to many.
Second, the set of techniques are too detailed to cover here but some example heuristics
these papers experiment with include the following: (i) the syntax used for providing the schema
(apparently putting “the pound sign # to differentiate prompt from response in examples yields impressive performance gains” 😀 go figure); (ii)
the number and selection of example (question, SQL) pairs, e.g., apparently there is a sweet spot in the number
of examples to provide; or (iii) the effects of standardizing the text in the prompt, e.g., indenting and using all lower case letters consistently
(apparently has minor but some effect). Yes, as interesting and important it is to learn how to use LLMs better, I still
can’t escape the following thought before going to bed: somewhere out there, some advisor might be torturing some graduate student
to check if the magical box produces better SQL with a pound sign vs double slashes!
Most work I found is on generating SQL. In contrast, I found no papers that do similar prompting study for query languages of GDBMS though I ran into two papers that are providing benchmarks for query languages of GDBMSs: (i) SPARQL; and (ii) Cypher). So a low-hanging fruit future work is the following:
Important Future Work 1: Similar prompting studies for query languages of graph DBMSs with a focus on recursive and unions of joins queries.:
In contrast to SQL queries, here, one should study various recursive queries that the query languages of GDBMSs are particularly good
at and union-of-join queries which are asked by omitting labels in the query languages of GDBMSs.
For example if you want to ask all connections between
your User nodes and User can have many relationships, such as Follows, SentMoneyTo, or SameFamily,
you would have to write 3 possible join queries in SQL and union them. Instead, you can write this query
with a very simple syntax in Cypher as
MATCH (a:User)-[e]->(b:User), where the omissions of the label on the relationship e indicates searching over
all possible joins.1
As a side note: In the context of any query language, including SQL, questions that require sub-queries are of particular interest as they are generally harder to write. Some of the papers I read had sections analyzing the performance of LLMs on nested queries but the focus was not on these. In prior literature there are papers written solely on text-to-SQL generation for nested queries (e.g., see the ATHENA++ paper). I am certain someone somewhere is already focusing solely on nested queries and that’s a good idea.
data.world Paper and Some Interesting Questions
In the remainder of the post I want to review the benchmark paper from data.world that focuses on text-to-SQL using LLMs. Unlike other papers out there that
study the effects of different prompting heuristics, this paper studies the effects of data modeling
on the accuracy of SQL queries generated by LLMs, which is closely related to GDBMSs.
Specifically, this paper is an evaluation of the performance of GPT-4 in generating SQL using no examples, i.e., zero-shot, with basic prompting over a standardized insurance database schema called The OMG Property and Casualty Data Model. See Figure 1 in the paper (omitted here) for the conceptual schema, which consists of classes such as Policy, Account, Claims, Insurable Object, among others, and their relationships. The paper has a benchmark of 43 natural language questions and compares 2 approaches to generate the SQL query. The below figure shows an overview of these approaches for reference:
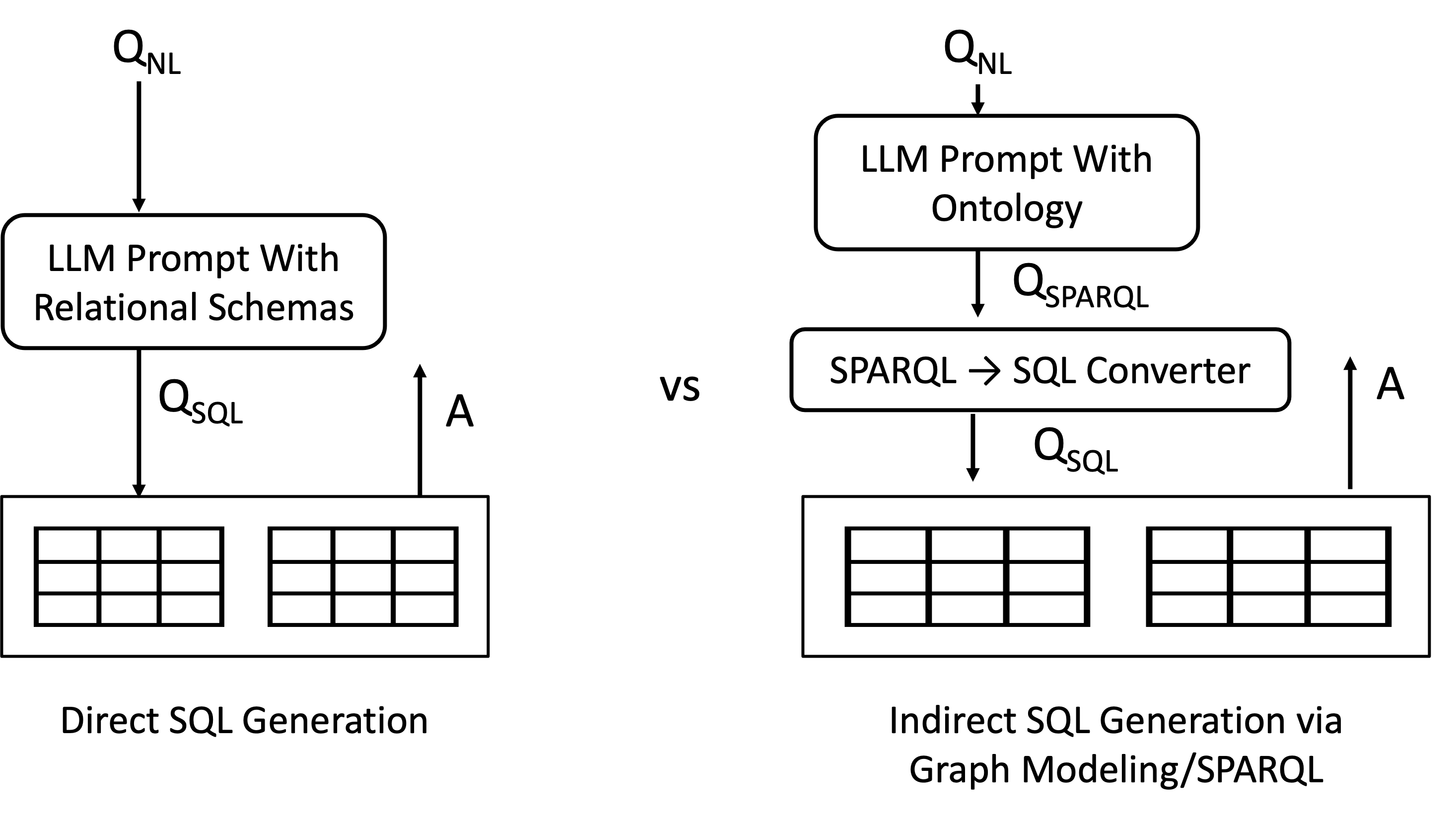
- Direct SQL Generation: In this approach, and the relational schema of the OMG database is given
to GPT-4. The schema is given in terms of
CREATE TABLEstatements, such as:
The full schema statements can be found here. GPT-4 is asked to generate a SQL query to answer . Copy-pasted from the paper, these prompts look as follows:CREATE TABLE Claim( Claim_Identifier int NOT NULL, Catastrophe_Identifier int NULL, ... Claim_Open_Date datetime NULL , ... PRIMARY KEY (Claim_Identifier ASC), FOREIGN KEY (Catastrophe_Identifier) REFERENCES Catastrophe(Catastrophe_Identifier), ...)Given the database described by the following DDL: <INSERT CREATE STATEMENTS FOR SCHEMA> Write a SQL query that answers the following question. Do not explain the query. return just the query, so it can be run verbatim from your response. Here’s the question: <INSERT QUESTION> - Indirect SQL Generation via Graph Modeling/SPARQL: In this approach, instead of the relational schema of the database, the same
database is modeled as an OWL ontology (OWL is short for Web Ontology Language).
Ontology is another term for schema when modeling data as a graph of classes and relationships between them. OWL is a W3C standard
and part of the RDF technology stack so OWL ontologies are expressed as a set RDF triples, such as:
The full ontology can be found here. GPT-4 is then asked to generate a SPARQL query , instead of SQL, for the same . The full prompt, again copy-pasted from the paper with some simplifications, looks like this:... in:Claim rdf:type owl:Class ; rdfs:isDefinedBy <http://data.world/schema/insurance/> ; rdfs:label "Claim" . in:claimOpenDate rdf:type owl:DatatypeProperty ; rdfs:domain in:Claim ; rdfs:range xsd:dateTime ; rdfs:isDefinedBy <http://data.world/schema/insurance/> ; rdfs:label "Claim Open Date" . in:hasCatastrophe rdf:type owl:ObjectProperty ; rdfs:domain in:Claim ; rdfs:range in:Catastrophe ; rdfs:isDefinedBy <http://data.world/schema/insurance/> ; rdfs:label "has catastrophe" . ...
As a last step, the authors have a direct mapping from to a SQL query . This is a quite straigh-forward step as the modeling as an ontology vs relational schema have direct translations from classes and properties to tables and columns.Given the OWL model described in the following TTL file: <INSERT OWL ontology as triples> Write a SPARQL query that answers the question. Do not explain the query. return just the query, so it can be run verbatim from your response. Here’s the question: <INSERT QUESTION>
An interesting comparison. There is some intuition for why one would be interested in the effectiveness of query generation through an ontology. Specifically, one of the well-known pre-LLM text-to-SQL papers ATHENA did something similar. Instead of SPARQL they had another query language over an ontology called Ontology Query Language, which was then mapped to SQL. So we can expect benefits of mapping natural language to an ontology first, where one can be explicit about class hierarchies and provide more information about metadata than standard relational modeling.
The results are even more interesting. The authors categorize their 43 questions into 4 quadrants based on 2 dimensions:
- Low vs. high question complexity: Questions that require only simple projections are low complexity. Those that require aggregations or math functions are high complexity.
- Low vs. high schema complexity: Questions whose SQL queries require up to 4 tables are low schema complexity. Those that require 5 or more joins are high schema complexity.
The accuracy results are shown below. Accuracy here is “execution accuracy” meaning that only the answers of the queries are checked against the ground truth answer. That is, even if the SQL query GPT-4 generated was actually not correct but by luck it computed the correct answers the paper takes it as correct (apparently happens very rarely in this study).
| Overall: 16.7% vs 54.2% | Low Schema Complexity | High Schema Complexity |
|---|---|---|
| Low Question Complexity | 37.4% vs 66.9% | 0% vs 38.7% |
| High Question Complexity | 25.5% vs 71.1% | 0% vs 35.7% |
Overall, the indirect SQL generation method through SPARQL is much more effective in this zero-shot setting. Not surprisingly, questions that require 5 or more joins are harder regardless of the method used and direct SQL cannot get any of those questions right. These are interesting results for an initial study on the effects of data modeling on LLMs’ accuracy on generating database queries. These results should give many researchers and practitioners ideas about how to replicate and validate/invalidate similar results under different settings, e.g., with few-shot examples and under different databases.
That said, one should ask, why? In fact, we should all be suspicious that merely modeling the same set of records with a different abstraction should have any visible effects. After all, by modeling the same records differently, one does not obtain or lose information. So if and when LLMs are smart enough, they shouldn’t care how the data was modeled. But for now, if a pound sign can make a difference, we should not be surprised modeling choices can have large impacts. As such, it is healthy to be suspicious and ask why. These motivate a few important questions I think are worth studying. My premise is that somehow if the differences are this large, it must be that the task for GPT-4 got simpler when asked to generate a SPARQL query. I can hypothesize about a few possible reasons for this:
-
Some queries require fewer tokens to write in SPARQL: One difference the query languages of GDBMSs often have is that certain equality conditions are implicit in the syntax, which means their
WHEREclauses are simpler for some queries. For example if you wanted to return the names of the Catastrophe that Claim with ID Claim1 has, in SPARQL you can write it as:SELECT ?name WHERE { <in:Claim1> in:hasCatastrophe ?catastrophe, ?catastrophe in:catastropheName ?name}In SQL you would write:
SELECT Catastrophe_Name FROM Claim, Catastrophe WHERE Claim.Catastrophe_Identifier = Catastrophe.Catastrophe_Identifier AND Claim.Claim_Identifier = Claim1Note that the
Claim.Claim_Identifier = Claim1equality condition is implicit in the<in:Claim1> in:hasCatastrophe ?catastrophetriple and theClaim.Catastrophe_Identifier = Catastrophe.Catastrophe_Identifiercondition is implicit in the fact that?catastropheappears both in the first and second triples in the SPARQL query. Such implicit equality conditions are common in the languages of graph query languages especially when expressing joins. For example in Cypher you can omit all join conditions in WHERE clauses as long as those joins have been pre-defined to the system as relationships. Instead you join records through the(a)-[e]->(b)syntax. It’s unclear how much this could matter but it is an immediate advantage of SPARQL that can explain why complex join queries are easier to generate in SPARQL than SQL.Side note: On the flip side, SPARQL can be more verbose in projections. For example, if you wanted to return the number, open and close dates of every claim, you’d write the following SQL query:
SELECT Claim_Number, Claim_Open_Date, Claim_Close_Date FROM ClaimIn SPARQL, you’d have to write both the names of the property you want to project and give it an additional variable as follows:
SELECT ?number, ?open_date, ?close_date WHERE { ?claim in:claimNumber ?number, ?claim in:claimOpenDate ?open_date, ?claim in:claimCloseDate ?close_date
- Graph modeling gives explicit names to foreign keys: There is a reason that database courses teach database modeling to students
using graph-based models, such as Entity-Relationship or UML models. First, humans think of the world
as objects/entities and their relationships. In some sense, these are higher-level models where relationships
between objects are denoted explicitly with explicit names (instead of as less explicit foreign key constraints).
For example, the implicit connection between Claims and
Catastrophes through the
FOREIGN KEY (Catastrophe_Identifier) REFERENCES Catastrophe(Catastrophe_Identifier)constraint was given an explicit English name:hasCatastrophein the ontology. This explicitness may make it easier for LLMs to understand the schema and generate SPARQL queries.
Both of these are qualitative hypotheses. However, there is a more immediate
reason the authors of this paper may have obtained such major differences between the two approaches they tried.
Intentionally or unintentionally, their ontology is simplified significantly compared to the relational schema they have.
For example, the Claim relation has Claim_Reopen_Date and Claim_Status_Code properties which are removed from the ontology.
Many such properties from the relations seem to have been removed, and the ontology overall looks simpler.
There are also several differences between the ontology and the relational schema that are confusing. For example
the ontology
has a class Agent and Policy objects are in:soldByAgent by some Agent objects (see lines 20 and 92). I cannot
see corresponding relations or columns in the relational schema. Unless I am missing something about how the prompts were given,
these are also likely to have important effects on the results and someone should fix and obtain new results
in a more fair comparison.
Let me next raise several high-level questions that I think are important:
Important Future Work 2: Rules of thumbs in data modeling to make LLM-generated queries more accurate. I think the higher-level question of studying the effects of data modeling in more depth is a very good direction. As LLMs get smarter, I would expect that the presence/absence of a pound sign or the style of English should matter less. These look more like syntactic differences that can be automatically detected over time. Modeling choices are more fundamental and relate to the clarity and understandability of the records that will be queried by the LLM. So identifying some rules of thumb here looks like the promising path forward. Let me list a few immediate questions one can study:
Important Future Work 2.1: Effects of normalization/denormalization. If the shortcoming of GPT-4 is generating queries with many joins, one way to solve this is to denormalize the relations into fewer tables and study its effects. Again, I’m thinking of same records just modeled differently with fewer tables. What happens if we reduce all data into a single table with dozens of columns and many value repetitions? Now all possible joins would have been performed so we’d force the LLM to write a join-less query with filters, distincts, and aggregations. What happens if we normalize the tables step-by-step until we get to a well known form, such as Boyce-Codd Normal Form? Do we consistently get better or worse accuracy?
Important Future Work 2.2: Use of views. In relational modeling, views are an effective way to have higher and simpler modeling of your records. Similar to a -[LLM]-> -[Direct Mapping]-> pipeline, one can test the effectiveness of -[LLM]-> -[Direct Mapping]-> pipeline.
Important Future Work 3: Use of Cypher as intermediate query language to translate to SQL. One reason to experiment with Cypher
in addition to SPARQL is that Cypher is, arguably, more similar to SQL than SPARQL but has the advantage that (common) join
conditions are implicit in the (a)-[e]->(b) node-arrow syntax. Yet Cypher does not have the verbosity of the SPARQL projections
I mentioned above (so you project properties the same way you project columns in SQL). In my world, all high-level query languages
look very similar to SQL, so eventually when LLMs are smart enough, or even today, I think these language differences
should have minor effects. However, graph query languages will likely continue to have major advantages when writing
recursive queries, as they have specialized syntax (e.g., Cypher has the Kleene star syntax) to do so. For those queries,
expressing first in Cypher and then mapping to SQL could lead to an advantage.
Final Words
Needless to say, in the next few years, the field will be flooded with work on how to use LLMs to solve the text-to-high-level-query problem. Many rules of thumb will emerge about how to prompt them correctly. The questions one can ask in this space is endless. I can speculate about it a lot, but I think it’s plausible that many of these rules of thumb, specifically the syntactic differences in prompting, can become obsolete very quickly as newer and more advanced LLMs that are better at speaking high-level database languages emerge. For example, it’s plausible that people will stop showing LLMs example (question, query) pairs each time they ask them to generate SQL once LLMs are better at speaking SQL.
However, the harder question of how to model the data so that its meaning is clear, and the queries that need to be written, are simpler, is more likely to remain a challenge for a longer time. I would not be too optimistic that there can emerge very clear answers to this question. How to model your data is part-art and part-science. Yet, some studiable questions, such as the effects of normalization, use of views or generating Cypher for recursive queries, can yield some important best practices that can be useful to developers building these systems.
In the next post, I will cover what I learned about RAG over unstructured data. Graphs and knowledge graphs are playing a more interesting role in that space. Until then, happy new year to all!
Footnotes
-
SPARQL syntax is different but a similar advantage exists by omitting type constraints. ↩