

Fully In-Browser Graph RAG with Kuzu-Wasm

DevOps Engineer & Co-founder of Kùzu Inc.

CEO of Kùzu Inc. & Associate Prof. at UWaterloo
We’re excited that members of our community are already building applications with the WebAssembly (Wasm) version of Kuzu, which was only released a few weeks ago! Early adopters to integrate Kuzu-Wasm include Alibaba Graphscope, see: 1 and 2, and Kineviz, whose project will be launched soon.
In this post, we’ll showcase the potential of Kuzu-Wasm by building a fully in-browser chatbot that answers questions over LinkedIn data using an advanced retrieval technique: Graph Retrieval-Augmented Generation (Graph RAG). This is achieved using Kuzu-Wasm alongside WebLLM, a popular in-browser LLM inference engine that can run LLMs inside the browser.
A quick introduction to WebAssembly
WebAssembly (Wasm) has transformed browsers into general-purpose computing platforms. Many fundamental software components, such as full-fledged databases, machine learning libraries, data visualization tools, and encryption/decryption libraries, now have Wasm versions. This enables developers to build advanced applications that run entirely in users’ browsers—without requiring backend servers. There are several benefits for building fully in-browser applications:
- Privacy: Users’ data never leaves their devices, ensuring complete privacy and confidentiality.
- Ease of Deployment: An in-browser application that uses Wasm-based components can run in any browser in a completely serverless manner.
- Speed: Eliminating frontend-server communication can lead to a significantly faster and more interactive user experience.
With this in mind, let’s now demonstrate how to develop a relatively complex AI application completely in the browser! We’ll build a fully in-browser chatbot that uses graph retrieval- augmented generation (Graph RAG) to answer natural language questions. We demonstrate this using Kuzu-Wasm and WebLLM.
Architecture
The high-level architecture of the application looks as follows:
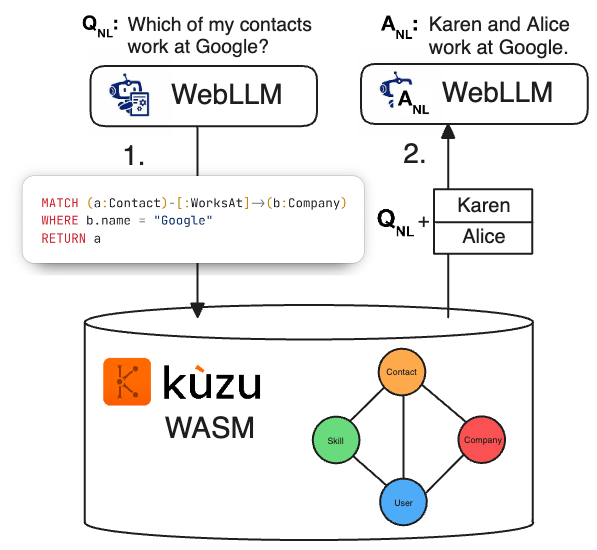
The term “Graph RAG” is used to refer to several techniques but in its simplest form the term refers to a 3-step retrieval approach. The goal is to retrieve useful context from a graph DBMS (GDBMS) to help an LLM answer natural language questions. In our application, the additional data is information about a user’s LinkedIn data consisting of their contacts, messages, companies the user or their contacts worked for. Yes, you can download your own LinkedIn data (and you should, if for nothing else, to see how much of your data they have!). The schema of the graph database we use to model this data will be shown below momentarily. First, let’s go over the 3 steps of Graph RAG:
- Q Q: A user asks a natural language question Q, such as “Which of my contacts work at Google?”.
Then, using an LLM, this question is converted to a Cypher query, e.g.,
MATCH (a:Company)<-[:WorksAt]-(b:Contact) WHERE a.name = "Google" RETURN b, that aims to retrieve relevant data stored in the GDBMS to answer this question. - Q Context: Q is executed in the GBMS and a set of records is retrieved, e.g., “Karen” and “Alice”. Let’s call these retrieved records “Context”.
- (Q + Context) A: Finally, the original Q is given to the LLM along with the retrieved context and the LLM produces a natural language answer A, e.g., “Karen and Alice work at Google.”
Implementation
Data Ingestion
The schema for our personal LinkedIn data’s graph is shown below:
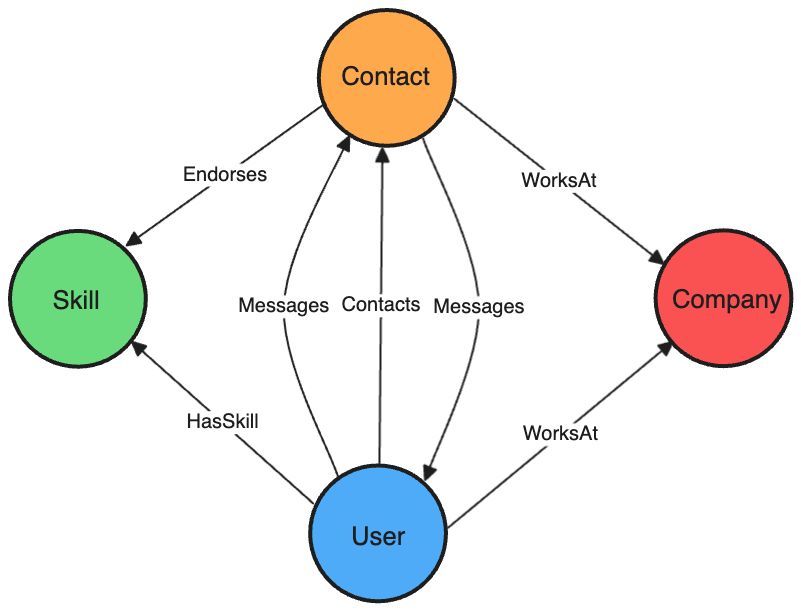
We ingest the data into Kuzu-Wasm in several steps using custom JavaScript code (see the src/utils/LinkedInDataConverter.js file in our Github repo):
- Upload CSV Files: Users drag and drop their LinkedIn CSV files, which are stored in Kuzu-Wasm’s virtual file system.
- Initial Processing: Using Kuzu’s
LOAD FROMfeature, the raw CSVs are converted into JavaScript objects. - Normalization: In JavaScript, we clean and standardize the data by fixing timestamps, formatting dates, and resolving inconsistent URIs.
- Data Insertion: The cleaned data is inserted back into Kuzu-Wasm as a set of nodes and relationships.
WebLLM Prompting
Our code follows the exact 3 steps above. Specifically, we prompt WebLLM twice, once to create a Cypher query Q, which is sent to Kuzu-Wasm. We adapted the prompts from our LangChain-Kuzu integration, with a few modifications. Importantly, we make sure to include the schema information of the LinkedIn database from Kuzu in the prompt, which helps the LLM better understand the structure and relationships (including the directionality of the relationships) in the dataset.
In this example, we represented the schema as YAML instead of raw, stringified JSON in the LLM prompt. In our anecdotal experience, for Text-to-Cypher tasks that require reasoning over the schema, we find that LLMs tend do better with YAML syntax than they do with stringified JSON. More experiments on such Text-to-Cypher tasks will be shown in future blog posts.
Observations
It’s indeed impressive to see such a graph-based pipeline with LLMs being done entirely in the browser! There are, however, some caveats.
Most importantly, in the browser, resources are restricted, which limits the sizes of different components of your application.
For example, the size of the LLM you can use is limited. We tested our implementation on a MacBook Pro 2023 and a Chrome browser.
We had to choose the Llama-3.1-8B-Instruct-q4f32_1-MLC model (see here for the model card),
which is an instruction-tuned model in MLC format. The q4f32_1 format is the smallest of the Llama 3.1 models that has 8B parameters
(the largest has 450B parameters, which is of course too large to run in the browser).
For simple queries, the model performed quite well. It correctly generated Cypher queries for the LinkedIn data, such as:
- How many companies did I follow?
- Which contacts work at Kùzu, Inc?
- Which skills do I have?
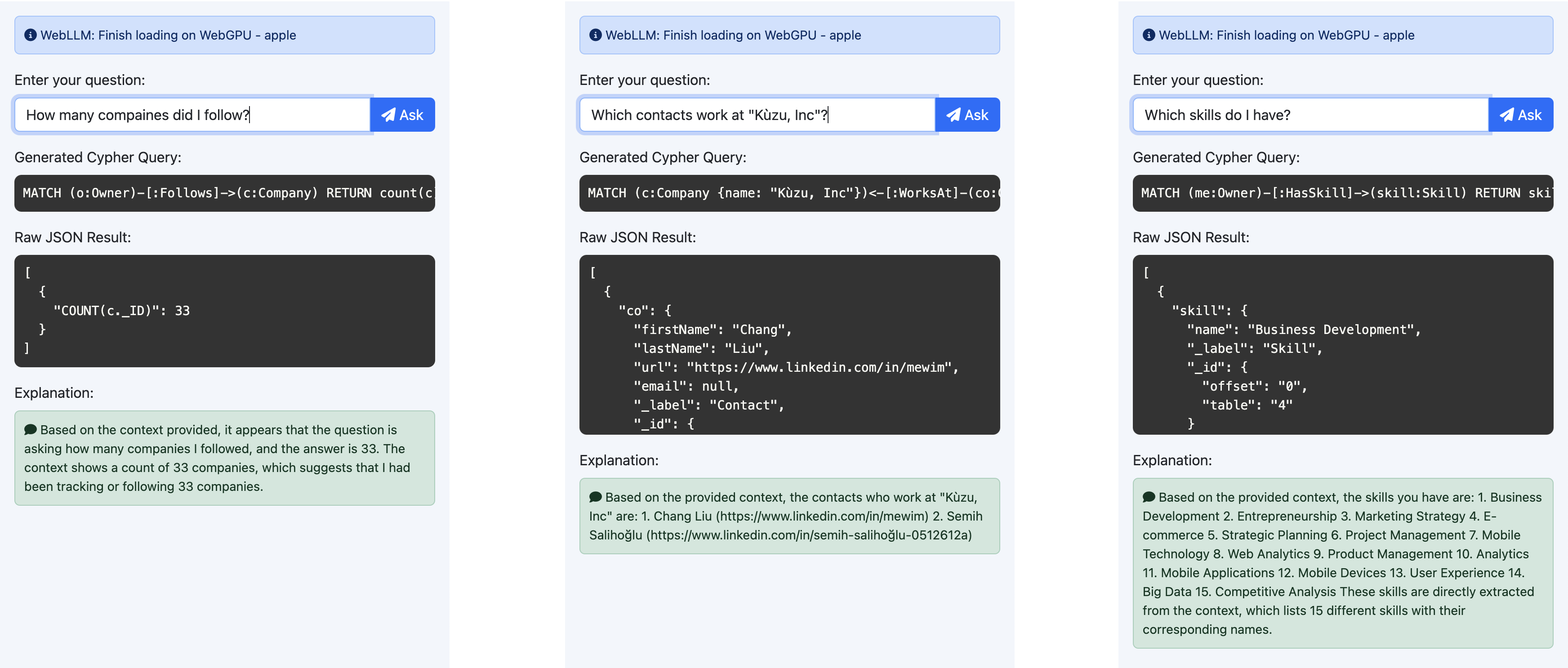
However, we saw that for more complex queries requiring joins, filtering, and aggregation, the model struggled to return a valid Cypher query. It often produced incorrect or incomplete Cypher queries for questions like: “Who endorsed me the most times?”. Token generation is also far slower than what you may be used to in state-of-the art interfaces, such as ChatGPT. In our experiments, we observed a speed of 15-20 tokens/sec, so generating answers took on average, around 10s.
Live demo
We have deployed this demo so you can test it in your browser:
- Live Demo: Drag and drop your LinkedIn data dump into
the app and start querying your personal graph. The demo also visualizes your data in a node-link graph view using
vis.js - GitHub Repository: The source code is openly available so you can experiment with it further. If you see better results with different models/prompts, we’d love to hear it!
Once the data is loaded, you can see a visualization that looks something like this:
Takeaways
The key takeaway from this post is that such advanced pipelines that utilize graph databases and LLMs are now possible entirely in the browser. We expect that many of the performance limitations of today will improve over time, with the wider adoption of WebGPU, Wasm64, and other proposals to improve Wasm. LLMs are also rapidly getting smaller & better, and before we know it, it will be possible to use very advanced LLMs in the browser. The next release of Kuzu will include a native vector index (it’s already available in our nightly build; see this PR for how to use it!). As a result, you can also store the embeddings of documents along with actual node and relationship records to enhance your graph retrievals, entirely within Kuzu. Using our upcoming vector index, you’ll be able to try all sorts of interesting RAG techniques, coupled with Kuzu-Wasm, all within the browser while keeping your data private. The sky is the limit!