


It’s been a very productive summer for all of us at Kùzu Inc., and we are excited to announce the release of Kuzu 0.5.0! In this (rather long) blog post, we will break down a significant list of updates that were made to Kuzu’s core in the last few months, including performance improvements. These include MVCC-based faster transactions, as well as several new features, such as attaching to remote Kuzu and SQLite databases, Python UDFs, scanning and outputting to JSON, scanning and loading from Polars DataFrames, and for a bonus usability feature, a progress bar in CLI and Kuzu Explorer! Without any further ado, let’s dive in.
Performance improvements
Performance has always been at the forefront of Kuzu’s design, and this release is no exception. We’ve made several improvements to the core storage and query engine to make it faster and more efficient. Below, we list two of these updates, starting with multi-version concurrency control-based (MVCC) transaction management.
MVCC-based transaction manager
In prior releases, Kuzu imposed certain limitations on transactions. The biggest one was that we immediately checkpointed after each write transaction, which could potentially block the entire system intermittently after each transaction. In cases where users have to perform many small write transactions, this could cause a lot more disk I/O and can trigger re-compressing column chunks, leading to slowdowns.
As of this release, we’re very happy to announce that we’ve begun reworking our core transaction and concurrency control mechanisms towards utilizing MVCC (based on this paper: Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems).
We will move towards a design similar to the one described in the paper, in phases. In this release, we’ve implemented the
core design in this paper, i.e., we now have version chains of node and relationship records and
timestamp-based version resolving, but we still limit write transactions
to be non-concurrent. Importantly, checkpointing is
now done automatically based on the WAL size, which can be configured by specifying CALL checkpoint_threshold=x,
where x is the threshold value in bytes. The default threshold value is 16 MB. Users can still enforce manual checkpoints via the CHECKPOINT statement,
deferring this operation to when there are no active transactions in the system.
These changes have led to significant performance improvements in data insertion. Below, we show the results of an experiment where we perform 100,000 insertions into a node table.
CREATE NODE TABLE Person (id INT64, name STRING, age INT64, net_worth FLOAT, PRIMARY KEY (id));Each insertion itself is an auto-transaction, and queries are executed through a single Kuzu connection.
// Pass each record's values as parameters as an individual transaction
CREATE (:Person {id: $id, name: $name, age: $age, net_worth: $net_worth})The timing numbers for the experiment below are from a Mac Mini Desktop with an Apple M2 Pro CPU and 32GB DRAM. We observed a 15x speedup in version 0.5.0 in comparison to the previous version.
| Kuzu Version | Time (s) | Speedup factor |
|---|---|---|
| 0.4.2 | 109.9 | — |
| 0.5.0 | 7.5 | 14.6 |
The good news is that this is not the end of it! In our next phase of development, we will turn our attention towards fully supporting MVCC, with no limitations on concurrent read and write transactions within a single process. Although at its core, Kuzu is designed to be very performant on read-heavy queries, moving to MVCC is also making Kuzu performant on transaction/write-heavy workloads!
Remote file system cache
Kuzu’s httpfs extension allows scanning and copying from a remote file system (e.g., S3 or HTTPS).
It also allows attaching to remote Kuzu databases, which is a new feature that’s part of this release (see below for more on this).
However, the performance of httpfs scan operations can be slow because these are scans of remote files, especially if the
operations are on an object store, say S3.
Therefore queries that involve operations on large files or many remote files can be slow.
To enhance performance, we introduced a new option that enables local file caching for files hosted on remote file systems.
The local file cache is initialized when Kuzu sends the file a read request for the first time.
Subsequent remote file operations that are within the same transaction will then be translated as local file operations on the local file cache1.
To illustrate the performance gains after enabling local file caching, here is a benchmark which scans an LDBC-10 Comment table
which is 2.1GB in size and is stored on a remote S3 bucket.
The benchmark is run on a machine with 2x AMD EPYC 7551 servers.
LOAD FROM 's3://kuzu-test/dataset/ldbc10/comment_0_0.csv'(HEADER=true, DELIM="|") RETURN *;
-- 279.11ms (compiling), 1401724.86ms (execution), 1402003.97ms (total)In the above query, Kuzu makes multiple remote file requests to S3 to scan
the whole file remotely. This takes 1,402 sec. Below are the performance numbers when turning the HTTP_CACHE_FILE option on.
CALL HTTP_CACHE_FILE=TRUE;
BEGIN TRANSACTION;
LOAD FROM 's3://kuzu-test/dataset/ldbc10/comment_0_0.csv'(HEADER=true, DELIM="|") RETURN *;
-- 27553.89ms (compiling), 4976.65ms (execution), 32530.54ms (total)
LOAD FROM 's3://kuzu-test/dataset/ldbc10/comment_0_0.csv'(HEADER=true, DELIM="|") RETURN *;
-- 169.61ms (compiling), 5066.42ms (execution), 5236.03 (total)
COMMIT;The first query after we start the transaction takes 32 sec, already a major improvement (43x). The compilation time takes
27.5 sec, which is primarily the time to download a copy of the file with one request to S3. Then the further execution
time takes 5 sec, which is the time to scan from the downloaded local disk. The second LOAD FROM from takes
only 5.2 sec (an additional 6.3x gain) since it’s completely executed on the local machine, i.e., no downloading takes place.
Features
This release also comes with a host of new features. Below, we list the main ones.
Remote Kuzu databases
Previously, Kuzu supported attaching to several remote relational DBMSs, e.g., Postgres and DuckDB.
These RDBMS extensions support scanning and copying data from these databases into Kuzu.
In this release, we’ve extended this functionality to attach to remote Kuzu databases as well. However, instead of
just scanning the tuples in these databases, you can also run read-only Cypher queries on these databases. Here’s a brief
overview of how you can query external Kuzu databases. First,
you install the httpfs extension and attach to a remote Kuzu database as follows:
INSTALL httpfs;
LOAD EXTENSION httpfs;
ATTACH 's3://kuzu-example/university' AS uw (dbtype kuzu);The above command attaches a remote Kuzu database located in an S3 bucket at s3://kuzu-example/university, and aliases it as uw.
Now you can query this uw database in Cypher as if it’s a local Kuzu database. That is, any Cypher query you run at this point,
will be executed against the remote uw database. For example, if you type:
MATCH (p:person) RETURN *This will scan the person node table in the s3://kuzu-example/university database.
To query your local Kuzu database again, you need to detach from the uw database (DETACH uw).
One potential use case of this feature is to query your backups. That is, you can create backups of your local Kuzu databases
remotely, say on S3, periodically. Then you can attach to any of these from the same script or a CLI and query them.
You can use the remote file system cache feature
(by running HTTP_CACHE_FILE=true),
which we covered above, to cache these remote Kuzu databases to improve
your query performance.
See this documentation page for more information on connecting to remote Kuzu databases.
Python UDFs
Earlier releases of Kuzu supported user-defined functions via the C++ API. In this release, we’ve extended the UDF functionality to the benefit of Python users as well. To register a Python UDF, it’s required to provide both a function signature and implementation. An example is shown below:
# Define your function
def difference(a, b):
return a - b
# Define the expected type of your parameters
parameters = [kuzu.Type.INT64, kuzu.Type.INT64]
# Define expected type of the returned value
return_type = kuzu.Type.INT64
# Register the UDF
conn.create_function("difference", difference, parameters, return_type)Once registered, the Python UDF can be used as you would use any other function in your Cypher queries:
result = conn.execute("RETURN difference(133, 119)")
while result.has_next():
print(result.get_next())
# Result
[14]In the above example, we define a function difference in Python that takes two integers and returns their difference.
We then register this function with the Kuzu connection object conn, explicitly declaring the function’s
expected type signature. Finally, we use the function to perform the desired operation via a Cypher query.
This can allow you to quickly extend Kuzu with new functions you need in your Python applications. However, before writing your own UDF, do check if an equivalent Cypher function in Kuzu exists, as native functions run faster than UDFs.
See this documentation page for more information on Python UDFs.
List lambda functions
In this release, we provide list lambda functions to aid in transforming, filtering, and reducing lists. The following list functions demonstrate this:
RETURN list_transform([1 ,2 ,3], x -> x + 1);
RETURN list_filter([1, 2, 3], x -> x > 1);
RETURN list_reduce([1, 2, 3], (x, y) -> x + y) You declare the lambda function as an argument inside the list function, as shown above. The list_transform function
applies the lambda function to each element in the list, list_filter filters the list based on the lambda function,
and list_reduce reduces the list to a single value based on the lambda function.
Scan and copy from DataFrames
If you regularly use Python DataFrame libraries to wrangle and transform your data, this section is for you! The first update is for Pandas users: We now support scanning from Arrow-backed Pandas DataFrames (earlier, you could only scan from numpy-backed Pandas DataFrames). Additionally, we introduced several great new features that improve developer experience when working with Pandas/Polars DataFrames.
LOAD FROM Polars DataFrames and PyArrow tables
In this release, we’re happy to announce that we now support scanning from either Pandas or Polars DataFrames, via the PyArrow interface. Numpy-backed Pandas DataFrame scanning, is still, of course, supported as before.
Below, we show an example of how to scan from a Polars DataFrame:
import polars as pl
df = pl.DataFrame({
"name": ["Adam", "Karissa", "Zhang"],
"age": [30, 40, 50]
})
# Return all columns of a Polars DataFrame
res = conn.execute("LOAD FROM df RETURN *")
print(res.get_as_pl())shape: (3, 2)
┌─────────┬─────┐
│ name ┆ age │
│ --- ┆ --- │
│ str ┆ i64 │
╞═════════╪═════╡
│ Adam ┆ 30 │
│ Karissa ┆ 40 │
│ Zhang ┆ 50 │
└─────────┴─────┘You can also scan from in-memory PyArrow tables the same way. See the documentation page for more information on these features.
COPY FROM DataFrames
LOAD FROM statements are used to scan external tuples and bind to variables
in Cypher queries. In contrast, COPY FROM statements are the fast way to do bulk data ingestion into Kuzu. Specifically,
COPY FROM copies external data or results of subqueries into a Kuzu node or relationship table.
In prior releases of Kuzu, if you wanted to copy data from a Pandas DataFrame to a Kuzu table using COPY FROM, you
had to use a LOAD FROM subquery and pass that subquery to
your COPY FROM statement. In the 0.5.0 release, we’ve
made this far simpler by allowing you to directly COPY FROM a DataFrame.
Before:
# Define a Pandas or Polars DataFrame
conn.execute("COPY Person FROM (LOAD FROM df RETURN *)")Now:
# Define a Pandas or Polars DataFrame
conn.execute("COPY Person FROM df")This feature works for copying data from either Pandas or Polars DataFrames, as well as PyArrow tables. Check out more details in this documentation page.
New Extensions
This release also introduces two new extensions (other than attaching to remote Kuzu databases, which we covered above): SQLite and JSON, whose key features are described below.
SQLite scanner
SQLite is one of the most widely deployed RDBMS systems, and we’re pleased to announce our new SQLite scanner, allowing you to easily scan and copy your data from your SQLite databases into Kuzu without having to export it to an intermediate format. To use this feature, first install and load the SQLite extension:
INSTALL sqlite;
LOAD EXTENSION sqlite;Attach a SQLite database by specifying the dbtype as sqlite:
ATTACH 'university.db' AS uw (dbtype sqlite);Once the SQLite databases is attached, you can access its tables directly in Kuzu. The following
command scans a table named person in the uw database that sits in SQLite.
LOAD FROM uw.person RETURN *Checkout more details in this documentation page.
JSON support
In this release, we’ve extended Kuzu to support scanning and ingesting data from JSON files, as well as writing data from Kuzu tables to JSON files. You can now scan a JSON file as follows:
LOAD FROM 'data.json' RETURN *;To ingest data from a JSON file, you can COPY FROM the JSON file using a familiar syntax:
CREATE NODE TABLE Example (a INT64, b STRING[], c DATE, PRIMARY KEY (a));
COPY Example FROM 'data.json';A subquery result can also be exported to a JSON file:
COPY (MATCH (n:Example) RETURN t.*) TO 'output.json';Checkout more details in this documentation page. In a future release, we also plan to release a feature that provides a JSON data type in the system, allowing users to store JSON documents as node or relationship properties.
Decimal data type
For users who require exact precision in their floating-point numbers, we’ve introduced the DECIMAL data type,
which works the same way as it does in other systems. You simply define
DECIMAL(precision, scale), where precision is the total number of digits and scale is the number of
digits to the right of the decimal point.
You can explicitly cast a number (either integer or float) to a DECIMAL as follows:
RETURN CAST(127.3, "DECIMAL(5, 2)") AS result;┌───────────────┐
│ result │
│ DECIMAL(5, 2) │
├───────────────┤
│ 127.30 │
└───────────────┘During schema definition, you can also specify a column’s data type as DECIMAL in your DDL.
When you insert numerical data into a DECIMAL column,
it’s implicitly cast to the DECIMAL type (based on the schema), allowing you to perform arithmetic operations on
them without losing precision.
DDL updates
Additional functions and features have also been added to the DDL in this release. Below, we list some of the important ones.
Create table if it does not exist
In prior releases, Kuzu used to throw an exception when trying to create a table whose name already
exists in the database, which required custom error handling logic. This is no longer the case, as
we now provide the CREATE ... TABLE IF NOT EXISTS
syntax to avoid an exception being raised if the table already exists.
CREATE NODE TABLE IF NOT EXISTS Person(name STRING, PRIMARY KEY(name));
CREATE REL TABLE IF NOT EXISTS Follows(FROM Person TO Person);See this documentation page for further details.
Drop table if it exists
Similarly, you can now drop a table without raising an exception if it doesn’t exist. This, in conjunction with the previous feature, should make it easier to manage your tables without having to check for their existence beforehand.
DROP TABLE IF EXISTS Follows;
DROP TABLE IF EXISTS Person;Note that you cannot drop a node table if there are relationship tables that depend on it — in the
above example, we made sure to drop the Follows table first before dropping the Person table.
See this documentation page for further details.
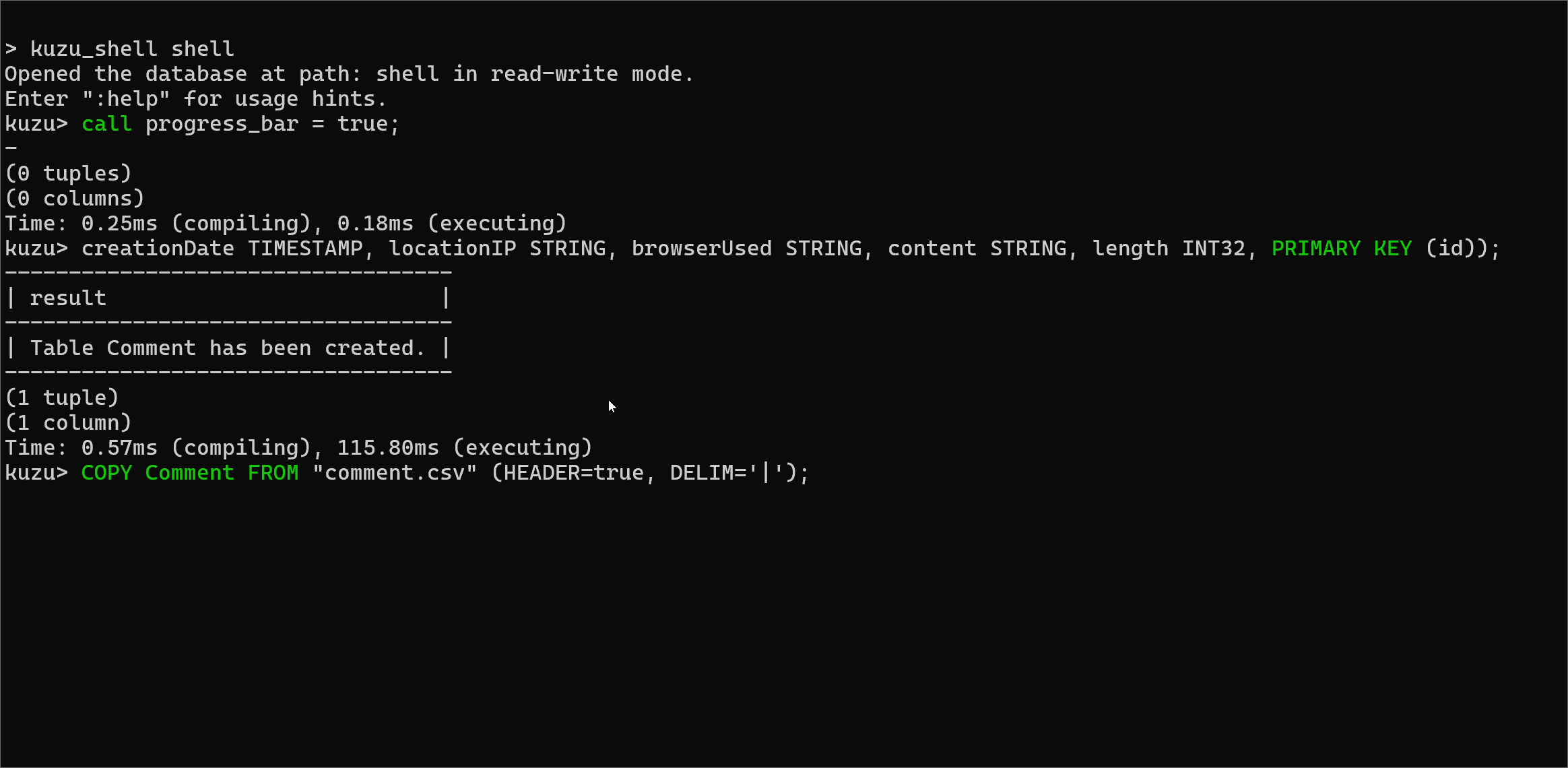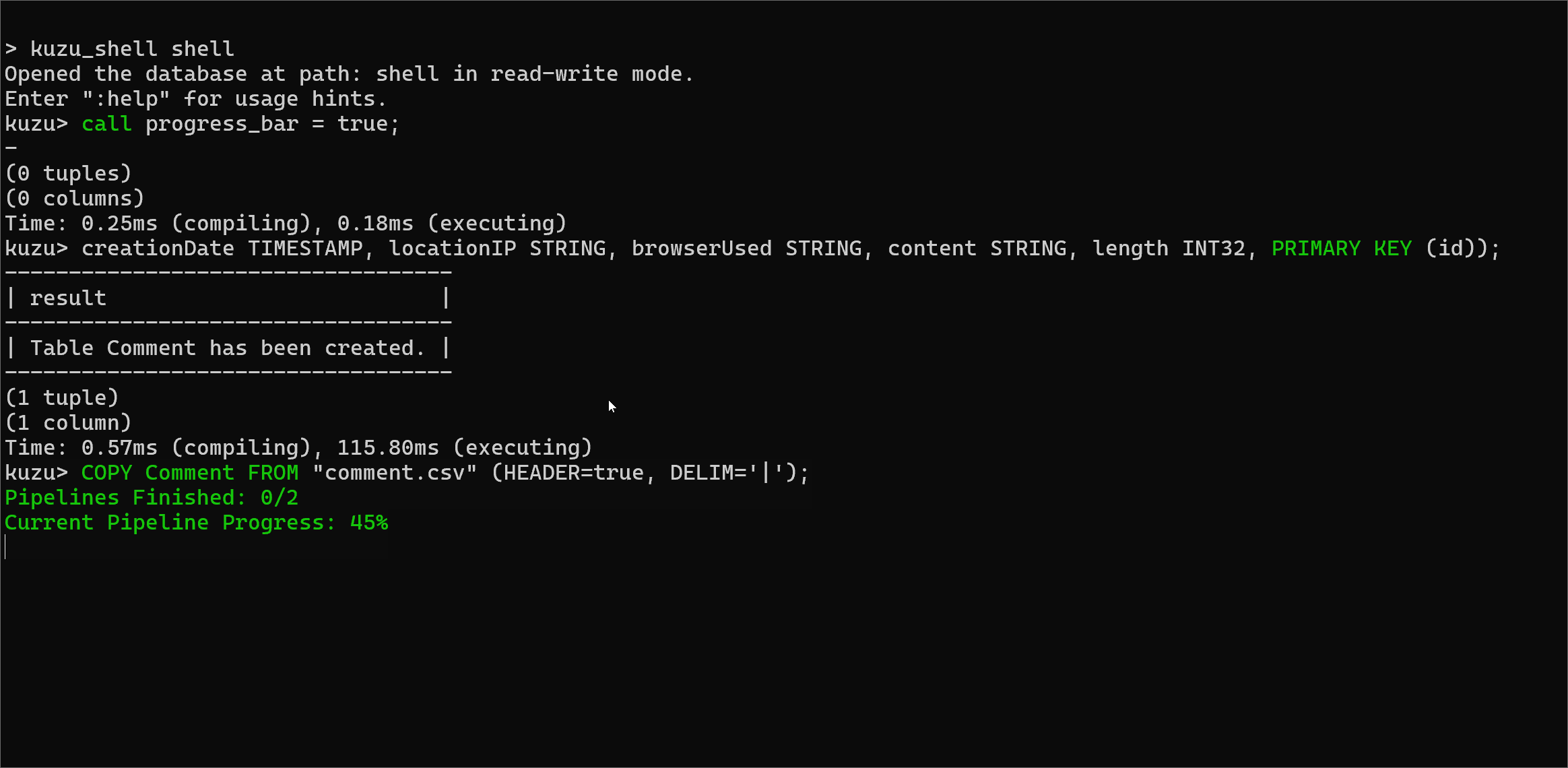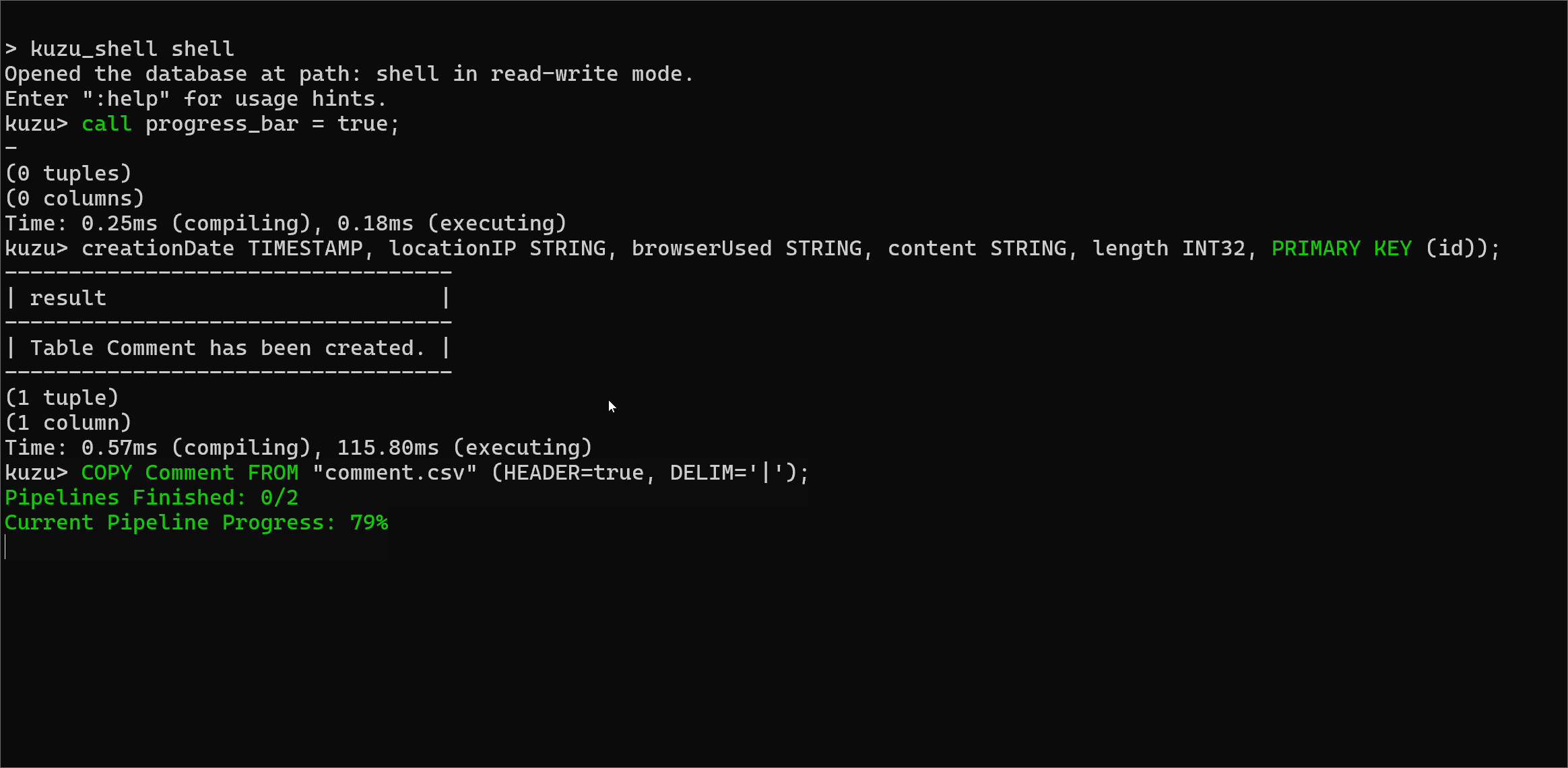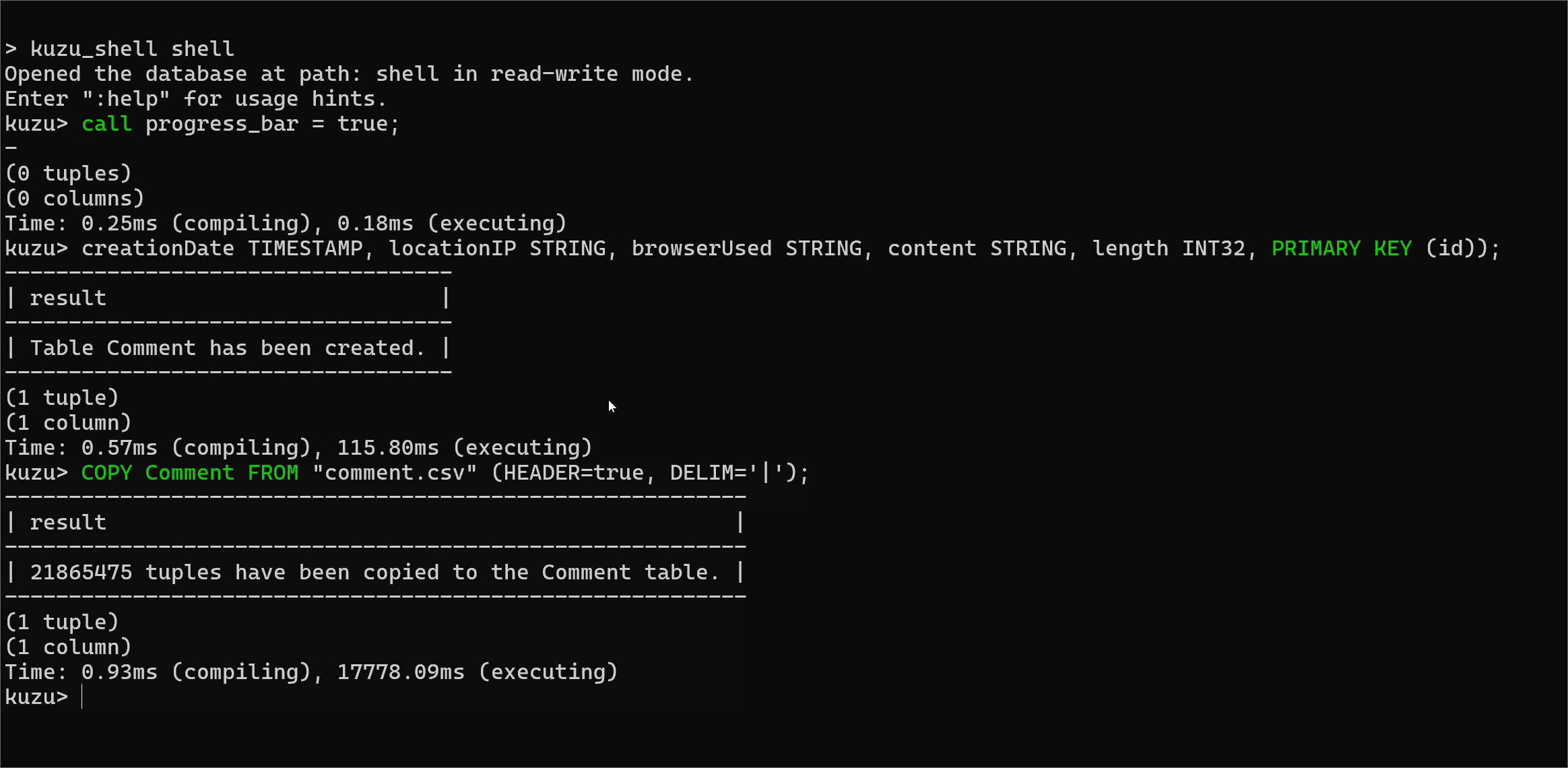
Progress bar in CLI and Kuzu Explorer
One frustrating issue in earlier versions was that during long-running queries, say a large bulk ingestion done in
a COPY FROM statement, you would not get any feedback on how long the query would take.
We now offer a progress bar that shows the percentage progress of a long-running query that’s being
executed. The progress bar is only available in the CLI and Kuzu Explorer, and you have to enable it prior to
executing the query, via the following command:
CALL progress_bar=true;For queries that take a significant amount of time to execute, the progress bar will now display the number of pipelines that have been executed (each query is broken down into one or more pipelines), as well as the percentage of the data processed in a pipeline, which gives an estimate for how much of a pipeline has executed.
C API improvements
Numerous improvements were made to the C API for this release. We highlight these below:
- Replaced return values with out parameters, simplifying object reuse
- Functions that can fail now return a
kuzu_statevalue, streamlining error handling - We now have utility functions such as
kuzu_date_t,kuzu_timestamp_t, andkuzu_interval_t
Join order hints
In certain cases, Kuzu could generate a sub-optimal join order when the obtained statistics are inaccurate at the optimization stage of a large graph query. Starting from this release, we provide the ability to specify join order hints to enforce a specific join strategy that bypasses Kuzu’s optimizer. In the coming months, we will be investing more time on our optimizer, but for now, this feature gives you a mechanism to explicitly control the join order Kuzu generates to improve the performances of your workloads. See the details here.
Closing Remarks
Whew, we just went over a lot of new features and improvements! But this blog post only scratches the surface of all that’s been added in this release. For a comprehensive list, check out our release notes on GitHub.
Our many thanks go out to the entire Kuzu team for their hard work in making this release possible. Hopefully, you find that these new features and improvements enhance your graph workflows and allow you to more easily bring your graph-based applications to production. In the coming months, we will continue to add more advanced functionalities to Kuzu, such as in-memory graphs and an inbuilt graph algorithms package within Kuzu. In the meantime, we recommend that you fire up a database using the newly released version and give these features a try! Do let us know if you have any feedback or questions on Discord, and have fun using Kuzu!
Footnotes
-
Cached files are visible per transaction. If you run a
LOAD FROMstatement on a remote file, then this file will be downloaded first and then scanned locally from the downloaded file. If you run the sameLOAD FROMstatement again, it will be downloaded again from the remote URL. This is because the second statement is executed as a separate transaction and we do not know if the already downloaded remote file has changed since the last time Kuzu downloaded it. If you need to scan the same remote file multiple times and benefit from caching across multiple scans, you can run all theLOAD FROMstatements in the same transaction. See the docs for more details. ↩