

Improving Text2Cypher for Graph RAG via schema pruning

AI Engineer at Kùzu Inc.
If you’re building Graph RAG pipelines with property graph systems, you’re probably using a Text2Cypher module to generate Cypher queries from natural language. Text2Cypher uses an LLM to dynamically generate Cypher queries that are aligned with both the user’s question and the graph schema. Once the relevant data is retrieved from the graph, it provides useful context to an agent for downstream tasks.
However, real-world graphs at enterprises can be quite complex — many node types, many-to-many relationships, and lots of properties. For agentic Graph RAG workflows, this complexity means more context must be fed to the context window of the Text2Cypher LLM, which can degrade query quality and negatively impact the retrieval outcome.
In this post, we show the results of our experiments with the latest LLMs, illustrating how schema pruning — the act of removing unnecessary parts of the graph schema and keeping only what’s relevant — can dramatically improve Cypher generation. We also frame schema pruning as a context engineering problem, and end with some recommendations for improving Text2Cypher in your own workflows. Let’s dive in!
Context engineering and information theory
Building reliable AI pipelines these days is all about context engineering, which is the act of providing an LLM’s context window with just the right amount of information for the next step. First, let’s gain an intuitive understanding of context engineering by looking at it from an information theoretic perspective1.
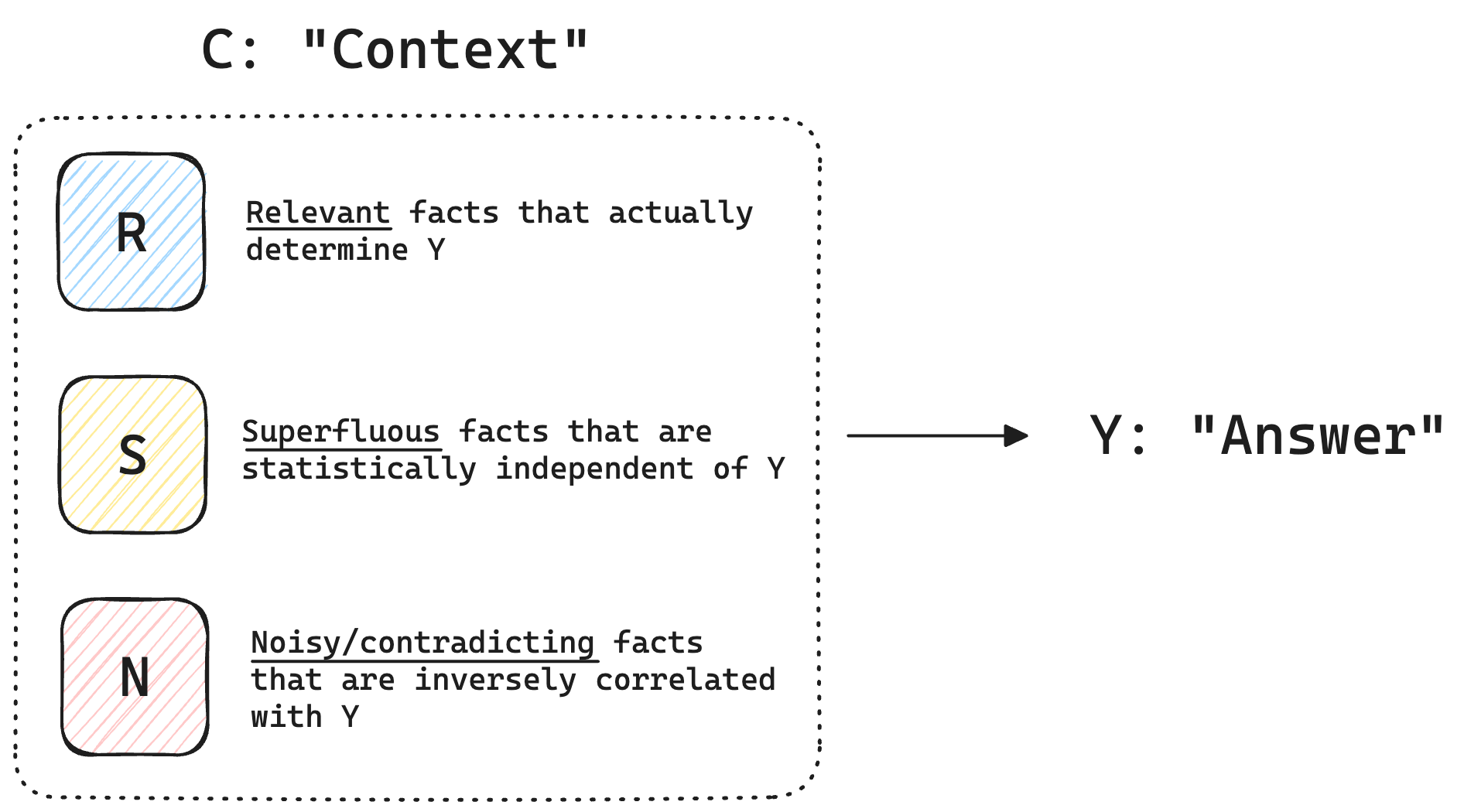
Let be the (ideal) answer you want the model to produce, and be the context (which is a random variable) given to the model to accomplish its task.
can be broken down into the following components:
- : Relevant facts that actually determine
- : Superfluous facts that are statistically independent of
- : Noisy/contradicting facts that are inversely correlated with
The goals of context engineering are as follows:
- Maximize the mutual information2 between and such that given , the model has a high probability of producing
- Maximize the amount of relevant information in that helps the model understand its task
- Minimize the amount of information in and that the model must process to arrive at
By understanding context in these terms, we can think about how to reduce the chances of the model hallucinating or getting misled by its context to produce the wrong answer.
Text2Cypher as a context engineering problem
In Text2Cypher, the context provided when constructing the LLM prompt consists of the following parts: the system instructions, the user’s question, and importantly, the graph schema. As mentioned earlier, real-world graph schemas are often complex and verbose, which can drastically increase the amount of and (noisy and superfluous facts) in the context.
The success of Text2Cypher is based on the following correctness criteria:
| Criterion | Description | Depends on |
|---|---|---|
| Syntactic correctness | Valid Cypher that can be executed on the graph database. | LLM’s ability |
| Semantic correctness | Must contain the correct node/relationship labels and their properties. | Context |
| Alignment | Results must be relevant to the given natural language question. | Context |
To successfully generate a Cypher query, an LLM must first align the graph schema with the user’s question to identify the parts of the schema that inform the Cypher generation process. It must then use its internal knowledge of Cypher syntax (based on its training data), while focusing its attention on the relevant parts of the graph schema, the user’s question and the special instructions in the system prompt, to succeed in its task. That’s a lot going on under the hood!
Below, we show experiments on how formatting the graph schema in various ways can significantly improve the quality of the Cypher generated, and discuss some of the trade-offs involved.
Experiments
For the experiments below, we’ll use the LDBC Social Network Benchmark (LDBC-1) dataset, which is commonly used to measure the performance of graph databases. The schema of the LDBC social network graph is reasonably complex and fairly verbose, so it’s a great way to test the effectiveness of various Text2Cypher strategies.
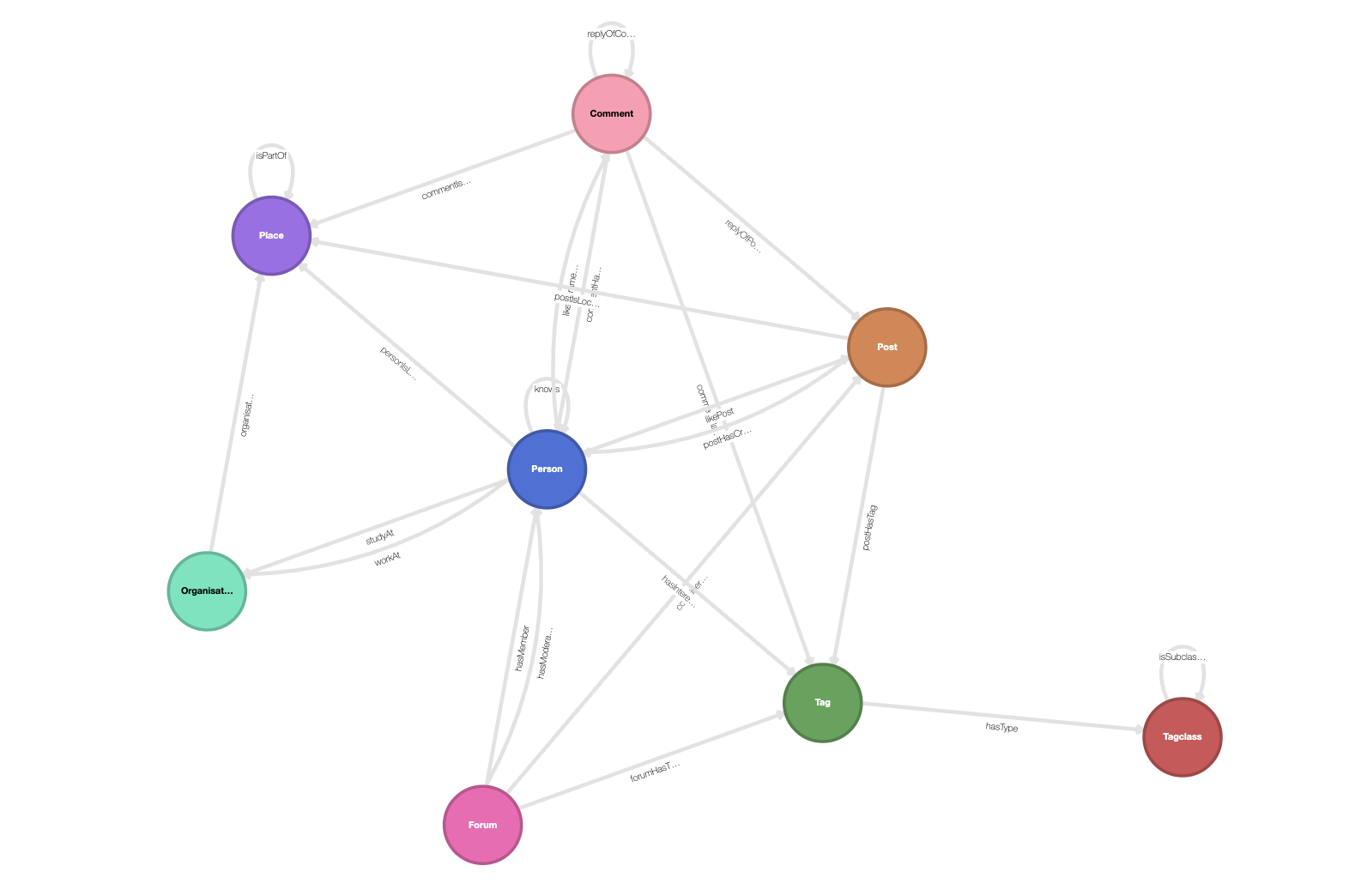
LDBC-1 graph schema
We ingest the LDBC-1 dataset into Kuzu, which contains 3.2 million nodes and 34.5 million relationships. There are 23 relationship labels and 8 node labels, each with numerous properties. Pictorially, the schema looks like this:
The actual schema in XML format is very verbose, so only a small subset of the schema is shown below to give a sense of how the schema is represented in the LLM prompt. The schema defines the structure of the graph (what directions the relationships can go in), as well as the properties that are available on each node/relationship label. See here to see the full schema in XML format.
<structure>
<rel label="workAt" from="Person" to="Organisation" />
<rel label="knows" from="Person" to="Person" />
</structure>
<nodes>
<node label="Person">
<property name="ID" type="INT64" />
<property name="firstName" type="STRING" />
<property name="lastName" type="STRING" />
</node>
<node label="Organisation">
<property name="ID" type="INT64" />
<property name="type" type="STRING" />
<property name="name" type="STRING" />
<property name="url" type="STRING" />
</node>
</nodes>
<relationships>
<rel label="workAt">
<property name="workFrom" type="INT64" />
</rel>
</relationships>Similar versions of the schema are also formatted in JSON and YAML formats, so that we can compare the results across different formats.
Query test suite
To test the effectiveness of our Text2Cypher implementation, we created a test suite of 30 questions, in three broad categories: a) exact matches, b) counting and c) binary (yes/no) questions. Some examples of questions in each category are shown below:
| Category | Question |
|---|---|
| Exact matches | What are the names of people who live in ‘Glasgow’, and are interested in the tag ‘Napoleon’? |
| Exact matches | In which places did the user ID 1786706544494 make comments that replied to posts tagged with ‘Jamaica’? |
| Counting | What is the total number of persons who liked comments created by ‘Rafael Alonso’? |
| Counting | What is the total number of forums moderated by employees of ‘Air_Tanzania’? |
| Yes/No | Did anyone who works at ‘Linxair’ create a comment that replied to a post? |
| Yes/No | Has the person “Justine Fenter” written a post using the “Safari” browser? |
| … | [see here for the full list of questions] |
The questions are designed to require anywhere from 2-5 hops of traversal in the graph, to gauge whether the LLM is able to appropriately join on the right node and relationship labels to answer the question. So these are a test of both the LLM’s knowledge of Cypher syntax and its reasoning capabilities.
Text2Cypher prompt
We use BAML, a programming language for structured text generation from LLMs, to manage the prompts for Text2Cypher. As described in an earlier post, BAML makes it simple to get high-quality structured outputs due to its emphasis on “schema engineering” thanks to its expressive type system.
The Text2Cypher prompt in BAML (after a few iterations via trial and error) looks like this:
class Query {
cypher string @description("Valid Cypher query with no newlines")
}
function Text2Cypher(question: string, schema: string) -> Query {
client OpenRouterGoogleGemini2Flash
prompt #"
Translate the given question into a valid Cypher query that respects the given graph schema.
<SYNTAX>
- Relationship directions are VERY important to the success of a query. Here's an example: If
the relationship `hasCreator` is marked as `from` A `to` B, it means that B created A.
- Use short, concise alphanumeric strings as names of variable bindings (e.g., `a1`, `r1`, etc.)
- When comparing string properties, ALWAYS do the following:
- Lowercase the property values before comparison
- Use the WHERE clause
- Use the CONTAINS operator to check for presence of one substring in the other
- DO NOT use APOC as the database does not support it.
- For datetime queries, use the TIMESTAMP type, which combines the date and time.
</SYNTAX>
<RETURN_RESULTS>
- If the result is an integer, return it as an integer (not a string).
- When returning results, return property values rather than the entire node or relationship.
- Do not attempt to coerce data types to number formats (e.g., integer, float) in your results.
- NO Cypher keywords should be returned by your query.
</RETURN_RESULTS>
{{ _.role("user") }}
<QUESTION>
{{ question }}
</QUESTION>
<SCHEMA>
{{ schema }}
</SCHEMA>
<OUTPUT_FORMAT>
{{ ctx.output_format }}
</OUTPUT_FORMAT>
"#
}The important pieces of the prompt include the system instructions, the user’s question, the graph schema, and the output format. The system instructions are a handcrafted list of requirements that the LLM must follow, with some Kuzu-specific instructions baked in, because the LLM has no prior knowledge of Kuzu.
BAML enables rapid iteration and experimentation during prompt engineering, and allows us to easily test different prompts and schema formats while swapping out multiple LLMs with ease.
Full graph schema results
The Cypher query output by BAML is executed via a Python script on the Kuzu database. To make experimentation easier, the execution logic is written as a pytest test suite, which sequentially runs Text2Cypher and the generated queries for the 30 questions in the test suite. Three popular formats of specifying the graph schema: JSON, XML and YAML, are tested. The passing/failing tests are colour-coded and plotted as a heatmap to help visualize the results as shown below.
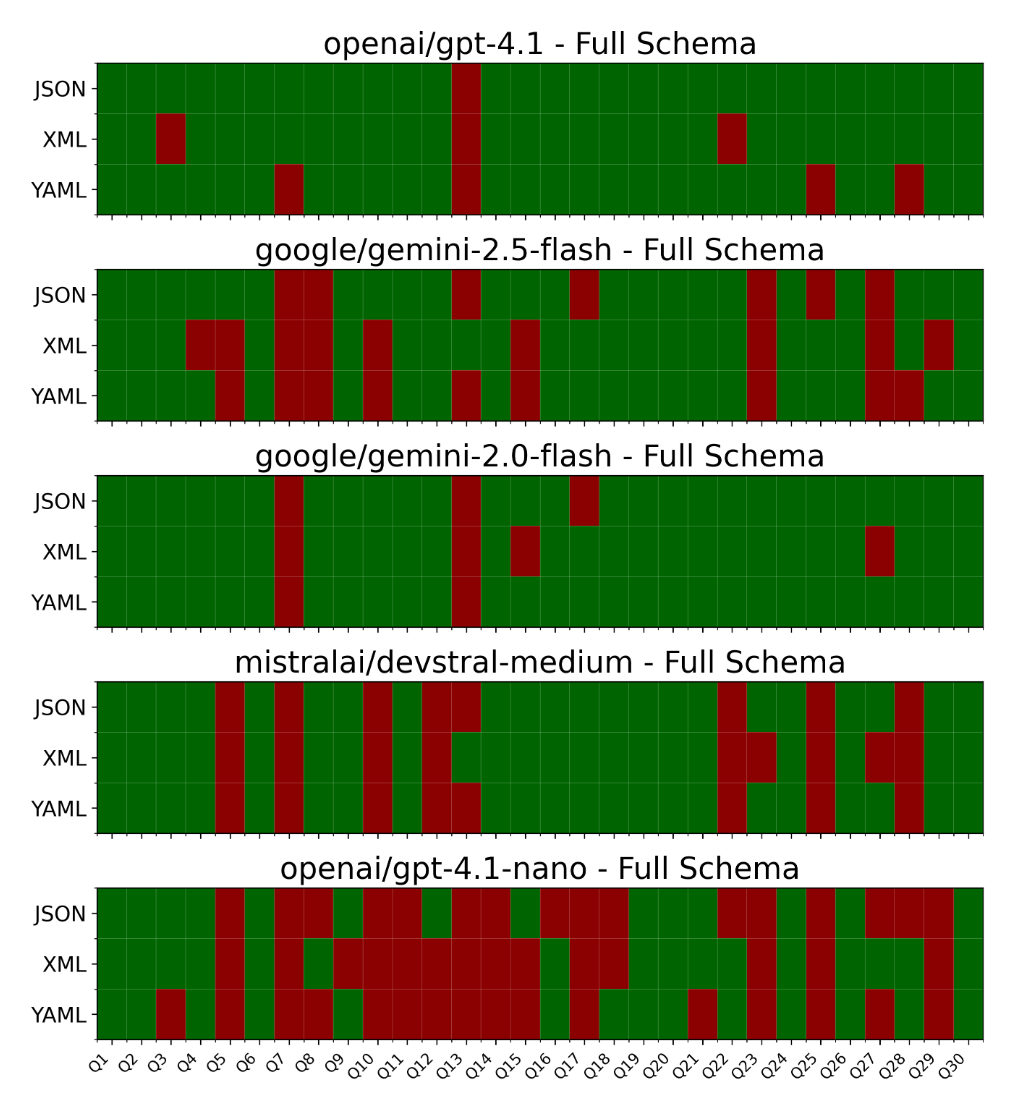
When we pass in the full graph schema as part of the prompts to several models, we can see that the large, more capable
models like openai/gpt-4.1 and google/gemini-2.0-flash are able to pass
many more tests than smaller models like openai/gpt-4.1-nano. Smaller, cheaper models like
mistralai/devstral-medium are also quite good at coding while being a fraction of the cost of flagship models
like openai/gpt-4.1. However, the error rate across many of these models is quite high, regardless of whether
the schema is in JSON, XML or YAML format.
Inspecting the results more deeply via the logs,
we saw that errors were mostly related to incorrect property names being used, and LLMs inverting the direction
of the relationships, despite the system instructions explicitly stating that the direction is important
and that it should focus on the from and to labels of the relationships.
Below is a query that google/gemini-2.0-flash failed on, but it almost got it right — the only mistake is that
the direction of the relationship between the Person and Forum nodes is inverted. Everything else is
semantically correct.
// What are the distinct IDs of persons born after 1 January 1990 who are moderators of Forums containing the term "Emilio Fernandez"?
MATCH (p1:Person)-[:hasModerator]->(f1:Forum) // !! Should be (p1:Person)<-[:hasModerator]-(f1:Forum)
WHERE p1.birthday > date('1990-01-01')
AND toLower(f1.title) CONTAINS toLower('Emilio Fernandez')
RETURN DISTINCT p1.IDThis is an indication that the full graph schema’s verbosity could lead to “context confusion” (especially in the smaller models), where the LLM attention is spread too thin across the context to achieve its goal.
Pruned graph schema results
As a natural next step, we prune the schema by passing the original (full) schema to another
BAML prompt whose only task is to retain the most relevant parts based on the user’s question. For example,
if the question is asking “How many comments were created by person ID 1042542534 in Berlin?”,
the pruned schema should only retain the Person, Comment, and Place node labels,
and the commentHasCreator and personIsLocatedIn relationship labels. This massively reduces the
amount of schema context (and the potential for context confusion) during query generation.
With BAML’s expressive type system, we can define custom nested types to represent the schema exactly as we want.
A GraphSchema is defined as a collection of Node and Relationship types that we want as output from our pruning LLM.
This way, the output from BAML is designed to be the same shape as the JSON
representation we obtained earlier from Kuzu via Cypher, allowing us to reuse our existing functions in the code. Very useful!

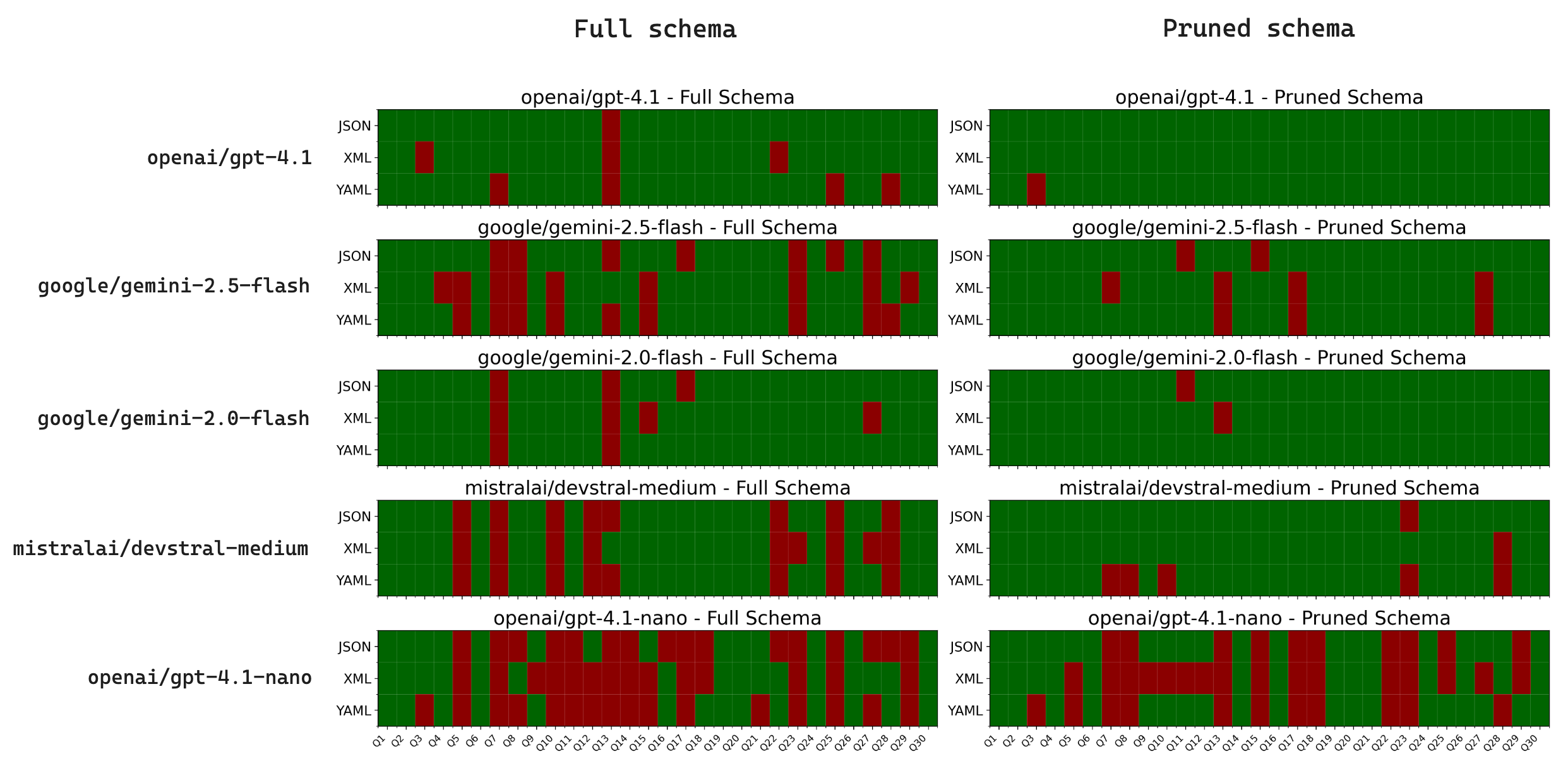
The experiments are run in the same way as the full graph schema experiments, and the results are plotted
as a heatmap once again. What immediately stands out is that the error rate is significantly lower across the board,
for all models! In particular, openai/gpt-4.1 and google/gemini-2.0-flash are able to pass 30/30 tests (perfect score)
using at least one of the schema formats, while mistralai/devstral-medium is able to pass 29/30 tests
when specifying the schema as JSON and XML.
Below, we show the only query that mistralai/devstral-medium failed to pass when using a pruned XML schema.
Despite the pruned schema being very small compared to the full schema, the LLM still fails to get the direction
of the (:Person)<-[:commentHasCreator]-(:Comment) relationship correct. The query is semantically correct
in every other way.
// Did any person from Toronto create a comment with the tag "Winston_Churchill"?
MATCH (p:Person)-[:commentHasCreator]->(c:Comment)-[:commentHasTag]->(t:Tag), // !! Should be (p:Person)<-[:commentHasCreator]-(c:Comment)
(p)-[:personIsLocatedIn]->(pl:Place)
WHERE toLower(t.name) CONTAINS 'winston_churchill'
AND toLower(pl.name) CONTAINS 'toronto'
RETURN COUNT(c) > 0All in all, it’s clear that schema pruning is a very effective way to improve the quality of Cypher generated by Text2Cypher pipelines.
Recommendations for better Text2Cypher
In this section, we summarize some of the lessons learned from the numerous experiments we ran and provide some recommendations to get the best out of LLMs when doing Text2Cypher.
Schema design for LLMs and humans
Because LLMs are trained on a lot of natural language data, they tend to capture semantics far better
when the paths read like a sentence in natural language. It’s worthwhile spending time carefully choosing the node
and relationship labels to help both humans and LLMs. Chances are, the LLM will correctly interpret the from/to directions
of the relationships more often than not, allowing them to reason more effectively on the user’s question
(based on several similar-looking failures we observed in the LDBC experiments).
The following table shows some examples of how the schema can be deliberately designed to help the LLM. Because LLMs generate in a left-to-right fashion, and they are primed to produce semantically meaningful tokens during training, the schema is much more likely to align with the LLM’s generation abilities when designed this way.
| Example | How it may look to the LLM | Recommendation |
|---|---|---|
(:Person)<-[:commentHasCreator]-(:Comment) | ”person commentHasCreator comment” | ❌ |
(:Person)-[:creates]->(:Comment) | ”person creates comment” | ✅ |
(:Forum)<-[:hasModerator]-(:Person) | ”forum hasModerator person” | ❌ |
(:Forum)-[:isModeratedBy]->(:Person) | ”forum isModeratedBy person” | ✅ |
Start with a large, capable model
Somewhat contrary to popular wisdom, it’s better to start with a large, capable model and understand the limits of the current state-of-the-art models, before embarking on a premature prompt engineering effort to get the most out of smaller models. Prompt engineering is tricky. If a larger model is good at generating Cypher queries in your domain, it’s possible to ship a working solution to production more quickly, and you can always cost-optimize (through prompt engineering and other techniques) later.
Tests, tests and more tests!
Work with domain experts to create a thoughtful, diverse set of questions and expected answers and incorporate this into a test suite early on in the development process. In the beginning, even a small test suite of 30-50 questions, as we showed in this post, can help understand a lot about where things are going wrong. Once you have real-world data from users in production, you can always augment the test suite to further analyze and improve the process end-to-end.
Schema pruning or compression
The schema format (JSON, XML or YAML) doesn’t seem to matter much, based on these experiments. What seems to matter a lot, however, is reducing verbosity of the schema. No matter how large the model’s context window is, a model will always do better when it has less information in the context to process.
Related to this, it’s always worth looking at ways to minimize superfluous and/or noisy information in the schema that’s presented to the Text2Cypher LLM. Pruning showed such good results in these experiments because it minimized context confusion (by eliminating similar-sounding property names, similar labels, etc.), allowing the model to focus on relevant tokens for the task at hand. Adding an additional schema pruning step upstream of Text2Cypher does increase latency by ~2x, but for the massive improvement in query quality (at least for the larger models), it’s well worth the trade-off.
Keep improving the prompt
Carefully inspect and iteratively improve the entire prompt (including system instructions) to ensure there is no contradicting information that can confuse the LLM. The system instructions provided in these experiments were arrived at after some iteration, after observing the failure modes across multiple models and prompts. However, as you iterate, you’ll likely find that parts of the prompt that existed before, might contradict or be redundant in the new version of the prompt. Applying the information theory concepts outlined above, you’ll find the context engineering process a lot more intuitive and natural to reason about.
Future work
Use Kuzu DDL as schema
Kuzu uses the structured property graph model and provides a DDL (data definition language) to define the schema of the graph. This contains all the right information that could serve as context for an LLM. We can potentially use Kuzu’s DDL schema (which is incredibly easy to generate via the CLI, and is already a part of the code base) as a prompt format instead of JSON/XML. Initial experiments with pruning the DDL schema are promising (see the code here), but more prompt engineering is needed to get this working as well as the JSON/XML schema formats on a wider range of questions.
Prompt optimization and beyond
Modern AI frameworks like DSPy (and soon, BAML3) provide the right set of primitives
to automatically optimize prompts, based on training data of good and bad examples. From the experiments
above, we can see the openai/gpt-4.1 model is a very powerful (though expensive) model that can generate
nearly perfect Cypher queries for complex schemas and questions with the right context engineering.
Using frameworks like DSPy, it’s possible to use larger, more capable models like openai/gpt-4.1 as “teachers” to generate
a suite of Cypher queries that can be used to optimize the prompts, so that smaller models like openai/gpt-4.1-mini
or openai/gpt-4.1-nano acting as “students” can get better at Text2Cypher and do the job of the larger model.
These optimized prompts are typically far superior to prompts written by a human, so this is a very promising area to explore in the future4.
Conclusions
As the AI landscape continues to evolve, it’s obvious that models’ capabilities will continue improving at a very rapid pace, and the cost of running them (as well as latency) will continue to decrease just as rapidly. The trade-offs among these different approaches will be a moving target, but with exciting new capabilities such as prompt optimization and fine-tuning becoming more and more accessible, it’s a great time to be exploring ways to get general-purpose models to write better Cypher, too!
If you’re working on these kinds of problems and are interested in building Graph RAG workflows, join us on Kuzu Discord and let’s chat!
Code
All the code to create the LDBC-1 graph, run the test suite and reproduce the experiments, is available in this repo.
Footnotes
-
See this video titled “Context Engineering: The Outer Loop” by Hammad Bashir for a good overview of the inner and outer loops of context engineering. ↩
-
Mutual information is defined as the amount of information obtained about one random variable by observing the other random variable. The concept was introduced by Claude Shannon in his 1948 paper “A Mathematical Theory of Communication”, but the term “mutual information” was coined by Robert Fano. ↩
-
The BoundaryML team is actively working on convenience features that make it easier for users to use BAML’s types (similar to DSPy’s signatures) to help users optimize prompts that are initially written by hand. Combining the rapid iteration and testing capabilities of BAML with prompt optimization at a more advanced stage of a project is a very powerful combination. ↩
-
DSPy goes a step further than most frameworks by providing multiple kinds of optimizers and uses the term “AI programs” to refer to the composable pipelines you can build with it. Using DSPy, it’s possible to fine-tune models, optimize tool usage and prompts, and much more. These techniques have positive implications for Text2Cypher and Graph RAG workflows, too! ↩