

Ephemeral graphs for data DAGs: How Bauplan leverages Kuzu for FaaS planning

Principal Engineer at Bauplan

CEO of Bauplan

CEO of Kùzu Inc. & Associate Prof. at UWaterloo

AI Engineer at Kùzu Inc.
Data pipelines as declarative DAGs
Data pipelines are the backbone of Artificial Intelligence and analytics use cases. In modern cloud architectures, such as the lakehouse, raw data in object storage is refined and transformed in a DAG, as practitioners turn raw datasets into cleaned ones for downstream models. A sample data pipeline is shown below:
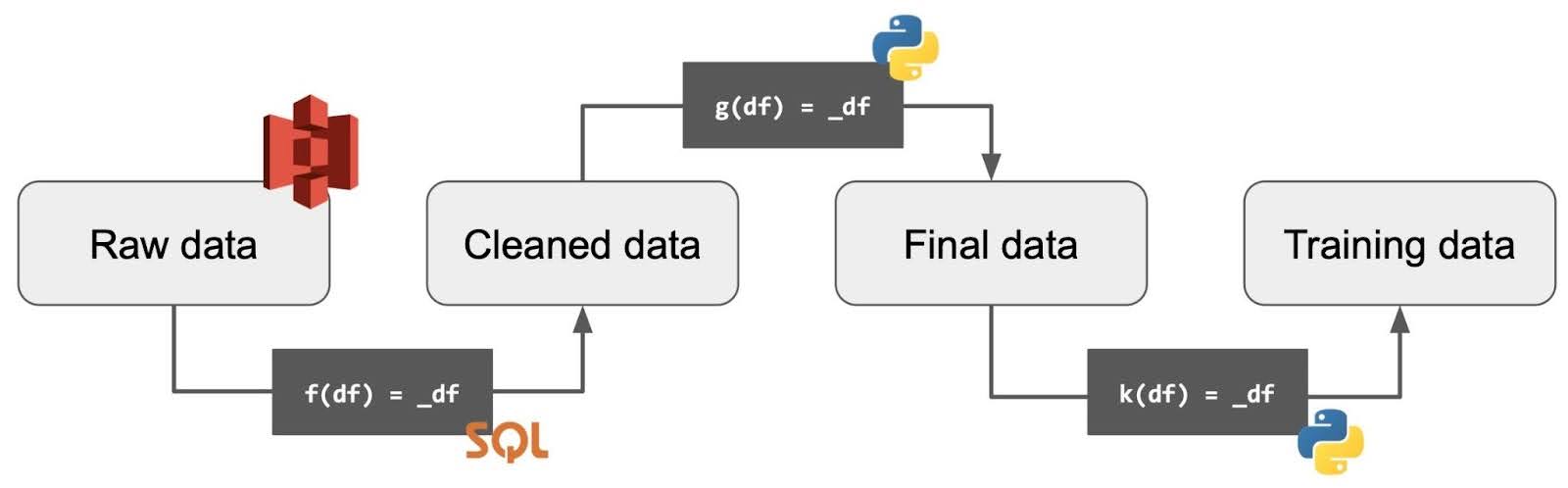
Bauplan is a lakehouse-as-code startup building APIs and function-as-a-service (FaaS) runtimes for data pipelines: in a nutshell, data practitioners write their transformation logic as simple functions, and Bauplan provides optimized data, runtime management and concurrent scheduling for them. Unlike traditional FaaS (such as AWS Lambda), however, Bauplan environments are declarative: I/O and package dependencies are specified through purpose-built abstractions, and it’s left to the platform to transform user code into a fleshed-out computational plan for execution.
The easiest way to understand Bauplan planning is to inspect a DAG. The following snippet is an initial implementation of the DAG shown in the above figure:
@bauplan.model()
@bauplan.python("3.10", pip={"pandas": "2.0"})
def cleaned_data(
# reference to its parent DAG node
data=bauplan.Model(
"raw_data",
columns=["c1", "c2", "c3"],
filter="eventTime BETWEEN 2023-01-01 AND 2023-02-01"
)
):
# the body returns a dataframe after transformations
return data.do_something()
@bauplan.model()
@bauplan.python("3.11", pip={"pandas": "1.5"})
def final_data(
data=bauplan.Model("cleaned_data")
):
return data.do_something()
# code continues with more functions…Even if it’s your first time reading this code, the intended semantics should be straightforward to appreciate:
- The DAG structure is declaratively expressed through function inputs (
final_datadepends oncleaned_data), and transformation logic is encapsulated in standalone functions; - Runtime properties are declaratively expressed through decorators: since functions are atomic, different Python interpreters (or Pandas versions) can coexist in one DAG;
- Data dependencies are declaratively expressed through tables, projections and filters:
cleaned_datadepends onraw_datain S3, but the code describes which columns and time-window are needed, not how to read the data from parquet files.
The declarative API creates a principled division of labor between the system (infrastructure and optimization) and the data scientist (business logic and choice of libraries). How do we then fill the gap between logical specifications (“T depends on table X, columns Y, Z”) and cloud operations (“read byte range 0-1414 from xyz.parquet in bucket B”)?
The challenge: From specifications to execution
Unlike most FaaS platforms, Bauplan has a Control Plane (CP) / Data Plane (DP) separation: user code is shipped to the CP, which parses the code and produces a plan (using Kuzu) — the plan is then sent to secure cloud workers in the DP for the actual execution. The below figure shows a simplified version of the CP. For a deeper architectural dive, check out the Middleware paper. Note that the CP never sees any actual data, it just sees the metadata.
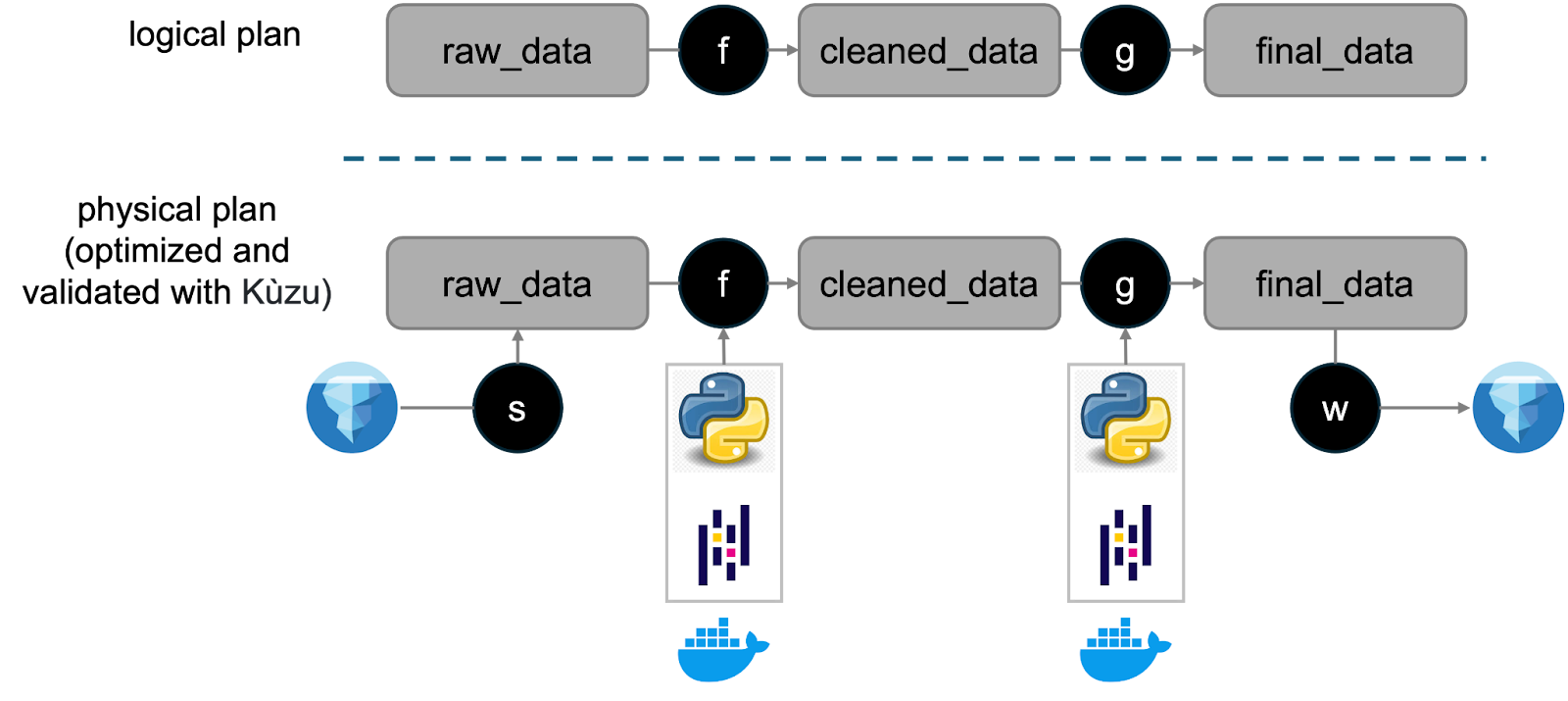
The system’s goal is to go from declarative code to validated instructions for the workers: for example the cleaned_data input should be transformed from this implicit dependency:
data = bauplan.Model(
"raw_data",
columns=["c1", "c2", "c3"],
filter="eventTime BETWEEN 2023-01-01 AND 2023-02-01",
)to something like the following pseudo-code:
# read data from S3
input_data = boto3.download_file(“lakehouse_bucket”, “raw_data_1.parquet”)
# make sure we select the right column and time window
selected_data = (
input_data["c1", "c2", "c3"]
.filter("eventTime BETWEEN 2023-01-01 AND 2023-02-01")
)
# feed the data to the user-defined function
cleaned_data(data=selected_data)Our initial solution was building custom code to parse functions, represent their dependencies, and check for interesting properties. For example, we could check the following:
- Rule 1 (Single root rule): The pipeline DAG can contain only one root table, i.e., a table with no parents.
- Rule 2 (Columns-in-leaf rule): Each column in the leaf tables should exist in their parents, and in the parents of their parents etc.
We represent the DAG with objects for columns and tables — columns are linked to their tables, and tables are linked together in the DAG dependency. The following is (generated) code that may be used to validate the columns recursively (full gist here).
# Traverse each table from root and validate columns at each step
def validate_columns(table: Table) -> bool:
# If the table has a parent, ensure all columns are a subset of the parent's columns
if table.parent:
parent_column_names = table.parent.get_column_names()
table_column_names = table.get_column_names()
if not table_column_names.issubset(parent_column_names):
missing_columns = table_column_names - parent_column_names
print(f"Error: Table '{table.name}' has columns {missing_columns} not found in its immediate parent '{table.parent.name}'.")
return False
# Recursively validate for each child
for child in table.children:
if not validate_columns(child):
return False
return True
# Start validation from the root
root = root_tables[0]
is_valid = validate_columns(root)Even without fully representing a real DAG, this snippet has a few undesirable properties:
- Data structures and checks are ad hoc: first, there is no standard way to represent nodes and graph-based inference; second, with each validation check we add, we incur in the cost of adding new traversal logic, which is hard to write (yay, recursion!), re-use and optimize;
- The code is slow, as Python objects, loops, GIL etc. are all introducing some overhead: when you throw in a dozen nodes in a real-world DAG, each with its own Python packages, you will start getting noticeable latency.
{kind=link}
Surely there’s a better way?
The solution: In-process graphs and planning-as-queries
The key insight we had is that FaaS planning with data DAGs boils down to graph representation and fast inference, i.e., path queries, in a graph — objects are naturally represented in a graph, so why not use a graph database? Moreover, our reasoning could be expressed using matching path patterns like those in Cypher, with better performance and more intuitive semantics than nested loops or recursion in an imperative language.
As every Bauplan run is an isolated end-to-end execution, planning graphs need to be instantiated only for the span of our checks - not dissimilar from our approach to OLAP, our ideal tool would allow ephemeral, in-memory graphs to be built, queried, and destroyed quickly. In other words, our graphs are “stateless” and exist only when processing a user request.
For these reasons, we needed a database that implements Cypher or a Cypher-like language and Kuzu was a perfect match for several reasons:
- Kuzu is an in-process (embeddable) database, i.e., it is a library, so the database runs as part of our control plane code. This means we don’t have to maintain a separate graph database server, which simplifies development as well as deployment.
- Kuzu is very fast: Kuzu can ingest and query data very quickly and also parallelizes queries well on multi-core machines. We were already able to use it when it did not support ephemeral in-memory databases, but since v0.6.0, they also have an in-memory mode, which made it even faster for our use case. See below for some concrete numbers on this point.
In short, we were able to benefit from using Cypher to express our rules declaratively and could benefit from a fast and simple to use database without the complications of setting up and maintaining a separate database server.
Re-written the Kuzu way, the imperative rules from above would look like the following. The code below assumes that we have created and populated a database with Tbl(id SERIAL, name STRING, cols STRING[]) nodes and Parent(FROM Tbl to Tbl) relationships:
import kuzu
# Create and populate a database with node table `Tbl` and relationship table `Parent`
# ...
# Rule 1:Check for the root table (a table with no parent)
res = conn.execute(
"""
MATCH (b:Tbl)
WHERE NOT EXISTS { MATCH (a)-[:Parent]->(b) }
RETURN count(*) = 1;
"""
)
# Some code to error if res.get_next() == True
# Rule 2: Ensure each table only uses columns that exist in its parent. Note that
# unlike the imperative code we don’t need a recursive query here; we only need
# to describe an operation to perform for each (p:Tbl)<-[:Parent]-(c:Tbl) pattern
res = conn.execute(
"""
MATCH (p:Tbl)<-[:Parent]-(c:Tbl)
WHERE NOT list_has_all(p.cols, c.cols)
RETURN *;
"""
)
# Some code to error if the answer is not empty.Leveraging Kuzu’s in-memory mode, creating a database with the relevant objects is a seamless operation; after its introduction, our planning became 20x faster! To get a sense of the actual complexity of graph processing in Bauplan, real-world DAGs often involve ephemeral graphs in which more than 500 Cypher statements (between node and relationship creation, pattern matching, graph updates etc.) are executed by Kuzu in ~1.5 seconds.
Once the graph is created, queries express validation rules as pattern matching over the graph. Note that the Cypher queries above for the rules are more explicit and express the rules at a higher level. While our developers now have to pay the price of learning enough Cypher to be dangerous, every additional check, transformation and validation can now be expressed uniformly in a high-performance framework: what if you want to track the type lineage of a column across nodes? Cypher query! What if you want to add user permissions for each table and guarantee that they are propagated properly to children? Cypher query …
There are other benefits of using Kuzu. On top of code simplification and standardization, we have built our own custom tools around the core graph engine: since our ephemeral graphs should be deterministically produced, at each Bauplan run, given the user code and a few environment variables, we built logging and debugging flows that allows us to precisely check our inference during development, and reproduce errors in live systems when debugging. In particular, we now maintain distinct table structures for different phases of plan generation, along with their relationships. This led us to develop what we call “certification process” — a comprehensive suite that validates the graph at various stages of construction.
The impact of this approach extends well beyond development and into our production environments. We’ve transformed our debugging capabilities by persisting both query logs and graph states to S3 during plan generation. Instead of reproducing issues by reconstructing the entire service context locally, we can now analyze production anomalies asynchronously by downloading the query log, rebuilding the exact graph generated at request time, and inspecting it programmatically and visually through Kuzu Explorer. This clear separation between plan generation logic and service code has significantly streamlined our debugging workflow, allowing us to diagnose issues with precision and efficiency.
What’s next? See you, graph cowboys!
We have been using Kuzu for over a year now in production and are actively extending our usage. While Kuzu in-memory graphs are already an important part of our CP (using Python), we envision a near future in which we expand its use to the DP as well (using Kuzu’s Golang API)): the possibility of sharing the same data structures and inferences across different components is an exciting development for our distributed architecture.
Want to know more about Bauplan? Read our blog, check out our latest papers, or just join our private beta to try it out!