

cognee 🧠 Kuzu: Transforming relational data into a knowledge graph

Growth & AI Engineer at cognee

Software Engineer at cognee

AI Engineer at Kùzu Inc.
Relational databases are powerful tools — efficient, reliable, and structured. They keep our data neat, tidy, and easy to query. But there’s a point at which the neatness and simplicity of rows and tables start limiting our ability to explore deeper connections. When your data is rich with complex relationships, traditional JOIN operations in SQL can quickly become cumbersome, slow, and difficult to maintain.
This is exactly where cognee steps in. We’re introducing an exciting new integration: cognee’s seamless database migration combined with the lightning-fast graph database Kuzu. Through an easy-to-follow example using the Chinook SQLite music database1, you’ll see firsthand how cognee effortlessly transforms your relational data into a comprehensive and dynamic knowledge graph that’s stored and managed in Kuzu. This graph can then be intuitively queried using natural language, unlocking deeper insights from your data.
We’ll assume that one or both of these powerful technologies are new to you, so before we dive into the data migration process, let’s briefly go over their capabilities. We’ll outline the core features of each tool and illustrate precisely how they work together to elevate your data from simple relational tables to an expressive, interconnected knowledge graph.
cognee: Building knowledge graphs from your data
cognee is an open-source platform for transforming data (structured or unstructured) into an interconnected knowledge graph with embedded semantic context. In essence, cognee serves as a memory layer for AI applications and agents, providing pipelines that extract information from sources, cognify it into a graph format, and load it into graph and vector databases (referred as the ECL pipeline). With minimal code, you can ingest existing data and end up with a queryable knowledge network. Some of cognee’s key capabilities include:
- Automated schema extraction and graph construction: cognee can connect to a relational database (currently supports SQLite or Postgres) and automatically extract its tables, columns, and relationships, then migrate this data into a graph structure. This means you can take an existing schema (for example, the Chinook sample database) and quickly turn it into a knowledge graph of nodes and edges representing the same information, with foreign keys becoming graph links.
- Integrated vector embeddings for semantic search: cognee doesn’t just create a graph; it also generates vector representations for textual content and attributes in your data. These embeddings capture semantic meaning, enabling similarity search and reasoning over the graph. Nodes and documents in the knowledge graph can be compared by content, so you can find related items even when keywords don’t directly match. This vector integration enriches the graph with a layer of contextual understanding.
- Natural language querying: Because of the above embeddings, cognee supports querying the graph using everyday language. Through its
cognee.searchAPI, you can ask questions or enter search phrases instead of writing database queries, and cognee will retrieve relevant results by combining vector similarity and graph traversal under the hood. This makes exploring the data intuitive for users who may not know formal query languages. - Modular pipeline and storage flexibility: cognee is designed to be storage-agnostic and highly extensible. It can ingest information from dozens of sources (databases, documents, images etc.) and uses a modular pipeline of tasks to process and link that data. Developers can define DataPoint models (using Python Pydantic classes) to map their domain, and cognee will handle creating the graph and vector index behind the scenes. It lets you plug in different back-end databases for storage — for instance, you could store the generated graph in-memory or in an external graph database like Kuzu or Neo4j, and likewise use a vector store such as Qdrant or Weaviate for embeddings. This flexibility allows you to choose the storage solutions that best fit your performance and scalability needs while cognee orchestrates the data flow. Its modular, provider-agnostic approach reduces the complexity of advanced data handling, so you can focus on building the application logic.
In summary, cognee provides an end-to-end framework to cognify your data — connecting to source databases, extracting their schema and content, constructing a knowledge graph, embedding context vectors, and enabling powerful semantic queries on the result. It essentially bridges the gap between traditional data stores and AI-friendly knowledge representations. After migrating Chinook into cognee’s graph format, you’ll be able to explore the music data with rich queries (for example, finding relationships between artists, albums, and genres, or asking questions about the data) with natural language.
Kuzu: A high-performance graph database for the knowledge graph
We’ll use Kuzu as the graph database and storage engine for the knowledge graph produced by cognee. Kuzu is a modern embeddable graph database built from the ground up for query speed and scalability on large graphs. In practical terms, Kuzu’s design makes it ideal for handling the kind of data we get from Chinook-as-a-graph, with efficient queries even as the graph grows. Some of Kuzu’s notable strengths are:
- Optimized architecture for big data: Kuzu’s core is built around a columnar storage format and novel indexing techniques. Instead of storing graph data in scattered nodes and pointers, Kuzu stores node properties and relationship links in columnar arrays on disk. It uses compressed sparse row (CSR) data structures to represent adjacency lists (who is connected to whom) efficiently. This modern storage format allows the database to scan through millions of edges quickly and perform set operations faster than traditional layouts. In essence, Kuzu organizes graph data like an analytical database, which yields fast retrieval of specific information even in huge datasets.
- Advanced query engine with parallelism: On top of the storage layer, Kuzu implements a vectorized and factorized query processor that takes full advantage of CPU capabilities. Queries are executed in a pipeline that processes data in batches (vectors) rather than one record at a time, and it uses novel join algorithms tailored for graph patterns. The engine is highly parallelized, meaning it can utilize multiple CPU cores to work on different parts of a query simultaneously. These techniques make complex, join-heavy queries (common in graph analytics) run significantly faster and more efficiently. In fact, Kuzu’s engineering is aimed at handling queries that involve many hops or combinations across the graph — scenarios that might bog down other systems — with ease. The end result is that even analytics that traverse large portions of the Chinook knowledge graph will remain responsive and scalable in Kuzu.
- Embeddable and easy to integrate: Unlike some graph databases that run as separate servers, Kuzu is an embedded database library. You can integrate it directly into your application process, which simplifies deployment and eliminates network overhead. Despite running in-process, it supports the popular property graph model and the Cypher query language for querying data. This means you can model data as nodes with properties and relationships (just as cognee outputs) and query them with familiar Cypher syntax. The embeddable, serverless design lowers the barrier to using Kuzu — there’s no need to manage a separate database server — while still providing full database capabilities (including ACID transactions for reliability). For our use case, we can run Kuzu as part of the Python environment when executing cognee’s pipeline, seamlessly storing the graph without external setup.
- Rich querying features (full-text and vector search): Kuzu goes beyond basic graph queries by incorporating features often needed in modern AI-powered applications. Notably, it has native full-text search and vector similarity search built into its engine. You can index textual data for keyword search and also store vector embeddings to perform nearest-neighbor searches — all within the graph database. Having these capabilities in one system means that if your knowledge graph nodes have descriptions or embeddings (as they will with cognee), Kuzu can directly handle queries like “find nodes with text matching X” or “find nodes with embeddings similar to Y” without needing an external search service. This tight integration of graph structure with text and vector search is a significant advantage for building intelligent applications. It enables scenarios like semantic question-answering over the graph or hybrid queries that filter by graph relationships and semantic relevance simultaneously.
- Structured property graph model: Kuzu implements the Cypher query language and defines a property graph data model, with added structure via a pre-defined schema - this is termed a “structured property graph model”. Defining a schema in Kuzu means that nodes and relationships are stored in tables, and all properties defined in these tables must have strict types that are known beforehand. The imposition of structure is what differentiates Kuzu from other graph systems that are more flexible and “schema-less”, but is also why Kuzu is extremely fast and can apply numerous optimizations to speed up query performance on expensive traversals. Because of these design features, Kuzu’s table-based schema definition language (DDL) is very close to way schemas are defined in SQL, making it a great fit if your data already sits in relational systems.
In summary, Kuzu provides a robust and high-performance storage for our knowledge graph. Its focus on scalability, fast graph traversals, and support for advanced query types (all within an embedded, easy-to-use package) make it well suited to serve as the target graph database when migrating from a relational system. By using cognee together with Kuzu, we get the best of both worlds: cognee handles the data transformation into a semantic graph with minimal developer effort, and Kuzu ensures that the resulting graph can be stored and queried efficiently, even as the data and query complexity grow. This powerful combination allows developers and data practitioners to explore and build upon various data sources in ways that were not possible with the traditional approaches alone — unlocking new insights and capabilities through the lens of a knowledge graph.
Walking through the cognee–Kuzu migration script
Now that we’ve covered what cognee is and how Kuzu fits in, let’s dive into the migration example to see how it all comes together. You can clone the cognee repo from here and run the Python script provided. The script takes a traditional relational database (a smaller version of Chinook sqlite dataset for a quick run) and transforms it into a knowledge graph stored in Kuzu. Here is the database structure from Chinook:
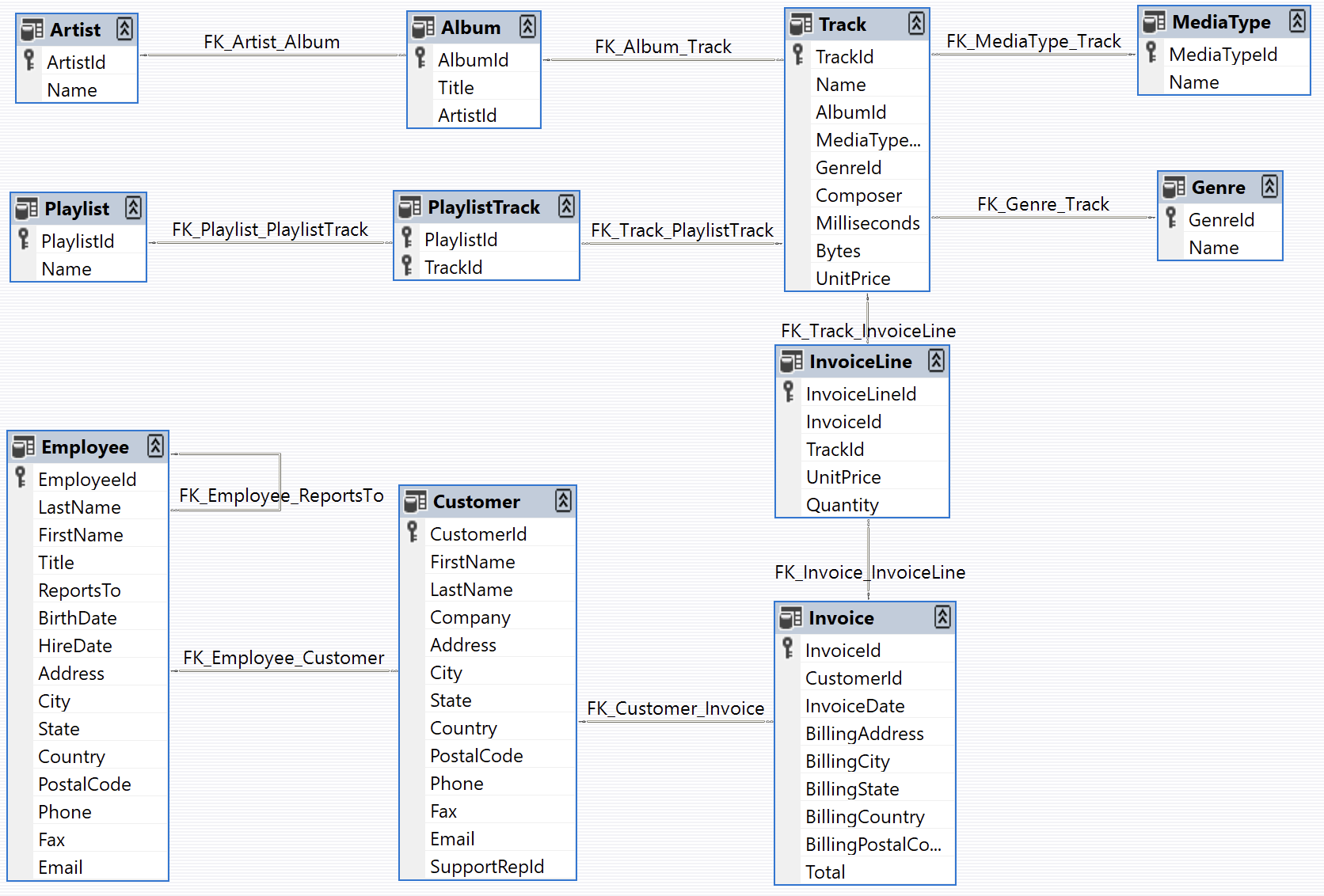
We’ll go through the example step by step. Even if you’re new to knowledge graphs, this breakdown will make the process easy to follow.
Preparing the data for migration
Configuring the env variables
After cloning cognee, copy/paste the .env.template file and rename it to .env. Add your OpenAI API key (if you want to use another LLM provider, check cognee docs for remote models or local models setup guideline). Download the smaller version of the Chinook database that is located here in the cognee repo
In the .env file, ensure you set the following variables:
GRAPH_DATABASE_PROVIDER="kuzu"
MIGRATION_DB_PATH="/{path_to_your_local_cognee}/cognee/tests/test_data"
MIGRATION_DB_NAME="migration_database.sqlite"
MIGRATION_DB_PROVIDER="sqlite"If you prefer using the original version or another database later, change the path and the name of the database accordingly. The rest of the .env file can stay as it is.
Connecting to the source database
In the example script, the first thing we do is to call get_migration_relational_engine() function, which looks at your configuration (from your .env file) and establishes a connection to the source DB. At this point, cognee is ready to read tables and rows from your sqlite database.
engine = get_migration_relational_engine()Clearing out old data
Before migrating anything new, we use cognee.prune.prune_data() and cognee.prune.prune_system(metadata=True) to delete previously stored nodes and edges from earlier runs and reset internal metadata. This ensures we’re starting fresh with an empty knowledge graph.
await cognee.prune.prune_data()
await cognee.prune.prune_system(metadata=True)Setting up the schema in the source DB
Next, we invoke create_db_and_tables()and create_vector_db_and_tables(), to set up the vector and graph databases in Cognee. By default, LanceDB is the vector database
and we’ve chosen Kuzu as the graph database in this example. Cognee will handle the chunking and embedding of the data to put into the vector database. For the graph database,
more details on the migration process are provided in the next section.
await create_relational_db_and_tables()
await create_vector_db_and_tables()Our environment is fully prepared and we’re ready to migrate the relational data!
Running the migration to Kuzu
Extracting the relational schema
The next step is to understand the structure of the source data, which cognee does by calling engine.extract_schema(). This function connects to the relational database and pulls out the schema — essentially a description of the tables, their columns, and the foreign key relationships between them. cognee will print out the schema it found, so you see a list or dict of table names with their fields and relationships. After this step the users can modify the returned value of the schema to choose which columns and foreign keys to migrate. This schema is important because it’s basically the blueprint for building the graph: each table will become a type of node in the graph, and each foreign key will become a link (edge) between nodes.
schema = await engine.extract_schema()Initializing the graph engine (Kuzu)
Now we switch to the graph side of things. The script calls get_graph_engine(), which under the hood checks our config and starts up the graph database. Because we set GRAPH_DATABASE_PROVIDER="kuzu" in the config, cognee will initialize a Kuzu database instance. At this moment, we have an empty graph database ready to receive data. We’re basically saying “Hey cognee, give me a graph object I can work with,” and cognee hands us a connection to Kuzu.
graph = await get_graph_engine()Migrating the data into the graph
This is the big moment — moving all the relational data into the knowledge graph. The script calls migrate_relational_database(graph, schema=schema), passing in the graph engine (our Kuzu instance) and the schema we extracted earlier.
from cognee.tasks.ingestion import migrate_relational_database
await migrate_relational_database(graph, schema=schema)During migration, cognee goes through each table defined in the schema and does two main things: it creates nodes for each record and edges for each relationship. For every row in every table, cognee will add a node into the Kuzu graph, labeled with the table name (for example, all customer records become Customer nodes). Then, for each foreign key relationship, it creates an edge linking the corresponding nodes. So if a Track table has a foreign key pointing to a MediaType table (as in the Chinook music database), the script will create an edge from each Track node to the appropriate MediaType node. These edges get a name or type corresponding to the foreign key. By the end of this migration function, every piece of data that was in the relational database now lives in the graph: all tables are represented as interconnected nodes in Kuzu.
Visualizing and Querying the Graph
Visualizing the new knowledge graph in Cognee
To help us inspect, we can generate a visualization of the graph using visualize_graph() . This visualization is a handy way to see the nodes and edges we just created easily on your browser. You’ll get a interactive graph view: dots representing each node (with labels like “Album” or “Track”), and lines connecting them to show the relationships (e.g. a line from a Track node to a MediaType node). It’s a quick sanity check and also just cool to see your data in graph form!
home_dir = os.path.expanduser("~")
destination_file_path = os.path.join(home_dir, "graph_visualization.html")
await visualize_graph(destination_file_path)
You can, of course, also use Kuzu’s own native browser interface2 (Kuzu Explorer) to explore the graph further.
Running a sample query on the graph
The whole point of moving relational data to a knowledge graph is to enable richer queries. cognee performs a search query using cognee.search() with query_type=SearchType.GRAPH_COMPLETION. This means we’re asking cognee (and the underlying LLM) to answer our query based on the graph’s content. Let’s understand this with an example. From the same directory where you ran the migration script, you can run the following code to query the graph using natural language
from cognee.modules.search.types import SearchType
import cognee
import asyncio
async def main():
results = await cognee.search(
query_type=SearchType.GRAPH_COMPLETION,
query_text="What track genres did the customer named Leonie Köhler purchase, and which artists are associated with these purchases?",
top_k=1000,
)
for result in results:
print(result)
if __name__ == "__main__":
asyncio.run(main())The following question is asked in natural language. The retrieval would need to be done in a way that the LLM can understand the connections in the data through the graph structure.
Q: “What track genres did the customer named Leonie Köhler purchase, and which artists are associated with these purchases?”
Leonie Köhler purchased tracks in the Rock genre. The associated artists with these purchases include AC/DC and Aerosmith.Because cognee now has the structure and data in Kuzu, it can interpret this question by looking at the graph’s nodes and relationships. Based on the retrieval from the vector and graph stores, the LLM is able to reason about the data and print out the answer in natural language.
By setting up the top_k parameter higher (we have used top_k with a value of 1000 for this example), you can get wider connections from your graph, meaning more hops in the graph. This kind of result shows the power of combining a knowledge graph with LLM-driven queries — you can ask high-level questions in natural language, and the system will use the graph structure to give you an informed answer.
Unlocking richer insights from your data with cognee and Kuzu
By walking through this example, we’ve seen how cognee takes a regular relational database and turns it into a knowledge graph backed by Kuzu, step by step. We connected to the source data, set up a fresh graph, migrated the records into nodes and edges, and then queried the new graph to get meaningful insights. Now, with your data living in a graph, you can continue exploring it with graph queries on Kuzu or natural language questions using cognee search, unlocking new ways to understand and use your information.
We’ll leave you with some links to the Kuzu and cognee communities. Do join them and share your thoughts with us!
- cognee: Join the Cognee Discord, and contact cognee if you want to learn more about preparing your data at scale for LLMs.
- Kuzu: Join the Kuzu Discord community and give us a shoutout in your circles if you’re looking for a high-performance graph database.
Happy graph exploring!
Footnotes
-
Chinook is a sample relational database that models a digital media store, including tables for artists, albums, media tracks, invoices and customers. The full database is quite large, so for this blog post (to save on LLM tokens, time and cost), we’ve made a smaller version of the database available in the cognee repo here. ↩
-
Learn more about Kuzu’s native browser interface, Kuzu Explorer, here. The Kuzu database created by Cognee is available in the path
./cognee/.cognee_system/databases/cognee_graph.pkl. You can use this directory path to launch Kuzu Explorer and visualize the graph there, if required. ↩