


How should we organize knowledge to provide the best context for agents?
Most current solutions — long context windows, vector stores, traditional RAG pipelines — offer semantically relevant recall that can be useful as context for agents, but can fall short when precision, reasoning, or explainability are required.
Limitations of Current Retrieval Systems
Let’s illustrate this with a real-world example. Consider an AI agent tasked with managing strategic client relationships. You ask:
“How is our relationship with Acme Corporation looking ahead of the contract renewal?”
The traditional RAG approach to retrieve context for the LLM would use vector embeddings: All communications with Acme get embedded into an abstract vector space, your question gets embedded the same way, and the system finds semantically similar content through proximity. You might get back:
- “Can you send over an updated SLA with the revised uptime guarantees?"
- "We’re feeling good about the renewal. The partnership’s been working well for us."
- "Your team’s been a big help this quarter — faster response times and smoother workflows across the board.”
These quotes sound relevant. But do they reflect the view of actual decision-makers? Are these the most important quotes and sentiments? Semantic similarity won’t answer those questions — it can’t tell you whose voice matters or why these quotes were retrieved.
Structured Recall with Knowledge Graphs
Now let’s layer a knowledge graph on top of the communication with Acme. Instead of retrieving content from an abstract vector space, we first model the core entities — people, contracts, meetings, communications — and their relationships.
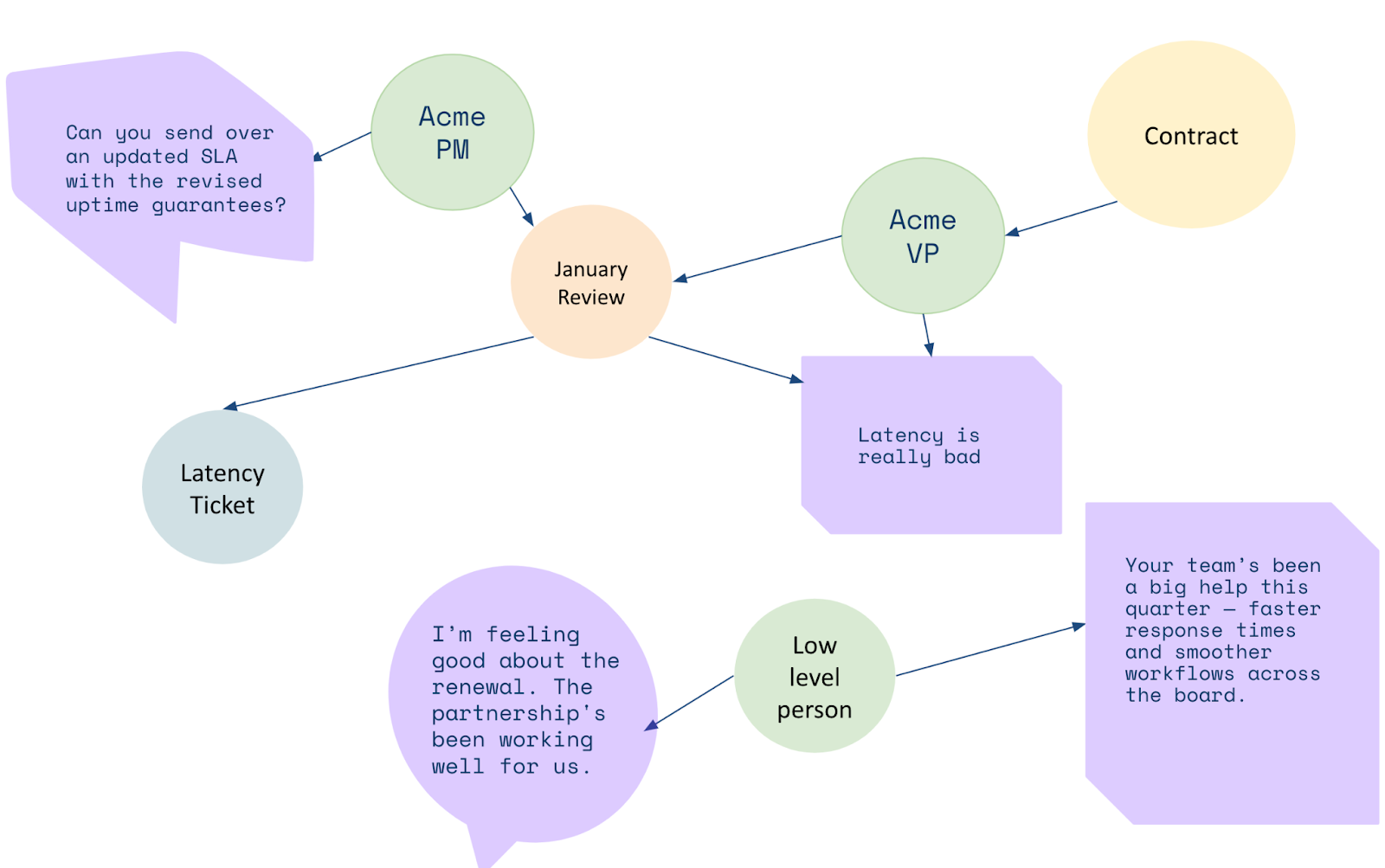
The graph shows that the contract is tied to a specific VP, the key decision-maker. The agent can now be much smarter and focus on the VP.
The graph provides the missing context that vectors alone cannot deliver. It gives completeness (all Acme-related people), precision (this particular VP), explainability (clear paths), and context (who, when, where).
Here is the example path the agent can now traverse:
Company (Acme) → Contract → Signatory (VP) → Meeting → Meeting notesPrecision via “Blast Radius” Vector Search
One of Kuzu’s most powerful capabilities is what we call “blast radius” vector search: vector retrieval anchored to a specific entity node. Instead of searching across the entire vector space, we constrain the search to the space surrounding a relevant node. The query runs only within that “blast radius”, which captures just the right amount of context for the downstream task.
The agent sees that the VP expressed concerns around latency during our last meeting with him — critical information that the previous method missed entirely. The graph also shows who else attended that meeting, when it happened, and what additional feedback was shared. Some of those positive quotes pulled via pure semantic search earlier? The graph reveals they came from someone with little influence over the renewal decision.
Why Graphs Matter
From a context engineering perspective, knowledge graphs offer several advantages over vector-only systems.
-
Authorship and Context: In embeddings, words aren’t necessarily attached to speakers and the larger context. In graphs, who said what, when, and where are first-class citizens — modeled explicitly. This mirrors how humans process the world: not just by interpreting isolated statements, but by grounding them in relationships, roles, and situations. Graphs bring the way agents process the world closer to how we do.
-
Explainability and Coverage: In embeddings, relevance is inferred through abstract similarity scores. In graphs, it’s traced through explicit entities, relationships, and paths. This makes them both understandable and improvable. As a developer — or as an agent — you can refine the graph over time to capture the nuances the task demands.
-
Dynamic structure: As new information comes in, the graph can evolve to show changing relationships and priorities, something that’s much harder to achieve with vector embeddings only.
Why Now
We’re seeing many companies building knowledge graphs specifically for agentic memory. From Fortune 500 companies implementing AI assistants to startups building the next generation of intelligent agents, the pattern is consistent: knowledge graphs make your agents smarter by exposing your rich, interconnected data to them.
Kuzu is ideal for this use case:
- Developer-friendly: Simple installation and integration (think
pip installrather than complex server setups). - Multi-index: Unified support for graphs, vector, and full-text search indices. Run queries like:
MATCH ... RETURN top-100 vectors within 2 hops of node X. - Fast: Optimized for real-world workloads.
- Deploy anywhere: Run in cloud, edge, serverless, embedded (in-process).
This is why we built Kuzu to bring the developer-friendly experience and speed of modern analytics tools — such as DuckDB — to graph-based agentic memory.
What’s Next
One interesting new application that’s emerging is the use of tools (i.e., databases) to help agents offload context from their memory — meaning they move the information from past interactions to a database, rather than trying to keep everything in the context window of the model. We think that graphs are a natural fit for constructing both short-term and long-term memory for agents, as seen in the example above.
Building agentic applications? We’d love to discuss your use case and how knowledge graphs can enhance your memory layer. Reach out me at [email protected] or just pip install kuzu to get started.
To learn more and engage with an active community building with agents and graphs, join us on Discord and star Kuzu on GitHub.